Amazon EKS Upgrades: Strategies and Best Practices 워크샵 내용을 기반으로 작성된 글입니다.
Amazon EKS 클러스터 업그레이드 워크숍의 목적은 고객에게 Amazon EKS 클러스터 업그레이드를 계획하고 실행할 수 있는 모범 사례를 제공하는 일련의 실험실을 소개하는 것입니다.
우리는 In-Place, Blue/Green 등 다양한 클러스터 업그레이드 전략을 탐구하고 각 전략의 실행 세부 사항을 자세히 살펴볼 것입니다.
이 워크숍에서는 EKS 테라폼 청사진, ArgoCD 등을 활용하여 전체 EKS 클러스터 업그레이드 프로세스를 안내합니다.
K8S Release
쿠버네티스는 1년에 3개의 마이너 버전 출시하며 가장 최근 3개 버전에 대해 release branches(패치) 지원

Patch Release를 보면 약 1년정도 패치를 지원 받을 수 있음
Version Skew Policy
kube-apiserver : HA apiserver 경우 newest 와 oldest 가 1개 마이너 버전 가능
- newest kube-apiserver is at 1.32
- other kube-apiserver instances are supported at 1.32 and 1.31
kubelet/kube-proxy : kubelet 는 apiserver 보다 높을수 없음. 추가로 apiserver 보다 3개 older 가능
- kube-apiserver is at 1.32
- kubelet is supported at 1.32, 1.31, 1.30, and 1.29
- 만약 apiserver 가 HA로 1.32, 1.31 있다면 kubelet 는 1.32는 안되고, 1.31, 1.30, 1.29 가능
kubectl은 kube-apiserver 버전 기준으로 한 버전 차이 내에서 지원
가상의 온프레미스 환경 K8S 업그레이드 계획
- 환경 소개 : k8s 1.28, CPx3대, DPx3대, HW LB 사용 중
- 각 구성요소와 버전
- Ubuntu 22.04 (kernel 5.15)
- Containerd 1.7.z
- K8S Version 1.28.2 - kubeadm, kubelet
- CNI : Cilium 1.4.z
- CSI : OpenEBS 3.y.z
- 애플리케이션 및 요구사항 확인 : 현황 조사 필요
목표 버전: K8S 1.32
1. 버전 호환성 검토
- K8S(kubelet, apiserver..) 1.32 요구 커널 버전 확인 : 예) user namespace 사용 시 커널 6.5 이상 필요 - Docs
- containerd 버전 조사 : 예) user namespace 에 대한 CRI 지원 시 containerd v2.0 및 runc v1.2 이상 필요 - Docs
(K8S 호환 버전 확인 - Docs)
- CNI(Cilium) 요구 커널 버전 확인 : 예) BPF-based host routing 기능 필요 시 커널 5.10 이상 필요 - Docs
(CNI 이 지원하는 K8S 버전 확인 - Docs) - 애플리케이션 요구사항 검토
2. 업그레이드 방법 결정 : in-place vs blue-green
- Dev - Stg -Prd 별 각기 다른 방법 vs 모두 동일 방법
3. 결정된 방법으로 업그레이드 계획 수립 : 예시) in-place 결정
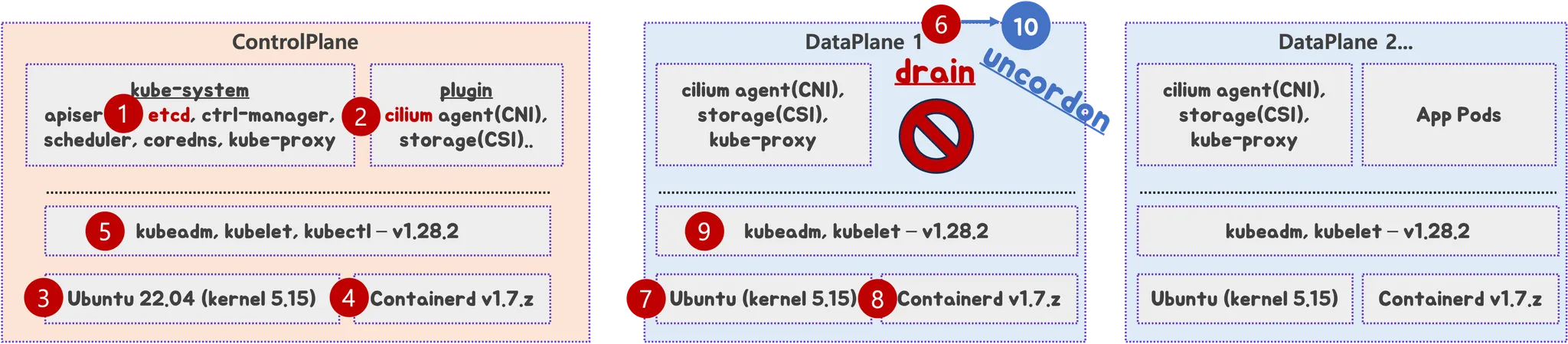
4. 사전 준비
- (옵션) 각 작업 별 상세 명령 실행 및 스크립트 작성, 작업 중단 실패 시 롤백 명령/스크립트 작성
- 모니터링 설정
- (1) ETCD 백업
- (2) CNI(cilium) 업그레이드
5. CP 노드 순차 업그레이드 : 1.28 → 1.29 → 1.30
- 노드 1대씩 작업 진행 1.28 → 1.29
- (3) Ubuntu OS(kernel) 업그레이드 → 재부팅
- (4) containerd 업그레이드 → containerd 서비스 재시작
- (5) kubeadm 업그레이드 → kubelet/kubectl 업그레이드 설치 → kubelet 재시작
- 노드 1대씩 작업 진행 1.29 → 1.30
- (5) kubeadm 업그레이드 → kubelet/kubectl 업그레이드 설치 → kubelet 재시작
- 작업 완료 후 CP 노드 상태 확인
6. DP 노드 순차 업그레이드 : 1.28 → 1.29 → 1.30
- 노드 1대씩 작업 진행 1.28 → 1.29
- (6) 작업 노드 drain 설정 후 파드 Evicted 확인, 서비스 중단 여부 모니터링 확인
- (7) Ubuntu OS(kernel) 업그레이드 → 재부팅
- (8) containerd 업그레이드 → containerd 서비스 재시작
- (9) kubeadm 업그레이드 → kubelet 업그레이드 설치 → kubelet 재시작
- 노드 1대씩 작업 진행 1.29 → 1.30
- (9) kubeadm 업그레이드 → kubelet 업그레이드 설치 → kubelet 재시작
- 작업 완료 후 DP 노드 상태 확인 ⇒ (10) 작업 노드 uncordon 설정 후 다시 상태 확인
7. K8S 관련 전체적인 동작 1차 점검
- 애플리케이션 파드 동작 확인 등
8. CP 노드 순차 업그레이드 : 1.30 → 1.31 → 1.32
- 노드 1대씩 작업 진행 x 버전별 반복
- kubeadm 업그레이드 → kubelet/kubectl 업그레이드 설치 → kubelet 재시작
- 작업 완료 후 CP 노드 상태 확인
9. DP 노드 순차 업그레이드 : 1.30 → 1.31 → 1.32
- 노드 1대씩 작업 진행 x 버전별 반복
- 작업 노드 drain 설정 후 파드 Evicted 확인, 서비스 중단 여부 모니터링 확인
- kubeadm 업그레이드 → kubelet 업그레이드 설치 → kubelet 재시작
- 작업 완료 후 DP 노드 상태 확인 ⇒ 작업 노드 uncordon 설정 후 다시 상태 확인
10. K8S 관련 전체적인 동작 2차 점검
- 애플리케이션 파드 동작 확인 등
Amazon EKS Upgrades: Strategies and Best Practices
실습 환경 정보 확인
- Getting started : 실습 환경 정보 확인
- 실습 환경 배포 : 오레곤 리전(us-west-2), EC2(IDE-Server) 접속
- IDE-Server 는 AWS CloudFormation Stack 으로 배포되었고, AWS EKS는 Terraform 으로 배포되어 있음.
- 실습 환경 배포 : 오레곤 리전(us-west-2), EC2(IDE-Server) 접속
IDE 정보 확인 : 버전(1.25.16), 노드(AL2, 커널 5.10.234, containerd 1.7.25)
#
whoami
pwd
export
# s3 버킷 확인
aws s3 ls
aws s3 ls s3://<버킷>
# 환경변수(테라폼 포함) 및 단축키 alias 등 확인
cat ~/.bashrc
# eks 플랫폼 버전 eks.44
aws eks describe-cluster --name $EKS_CLUSTER_NAME | jq

#
eksctl get cluster
eksctl get nodegroup --cluster $CLUSTER_NAME
eksctl get fargateprofile --cluster $CLUSTER_NAME
eksctl get addon --cluster $CLUSTER_NAME
#
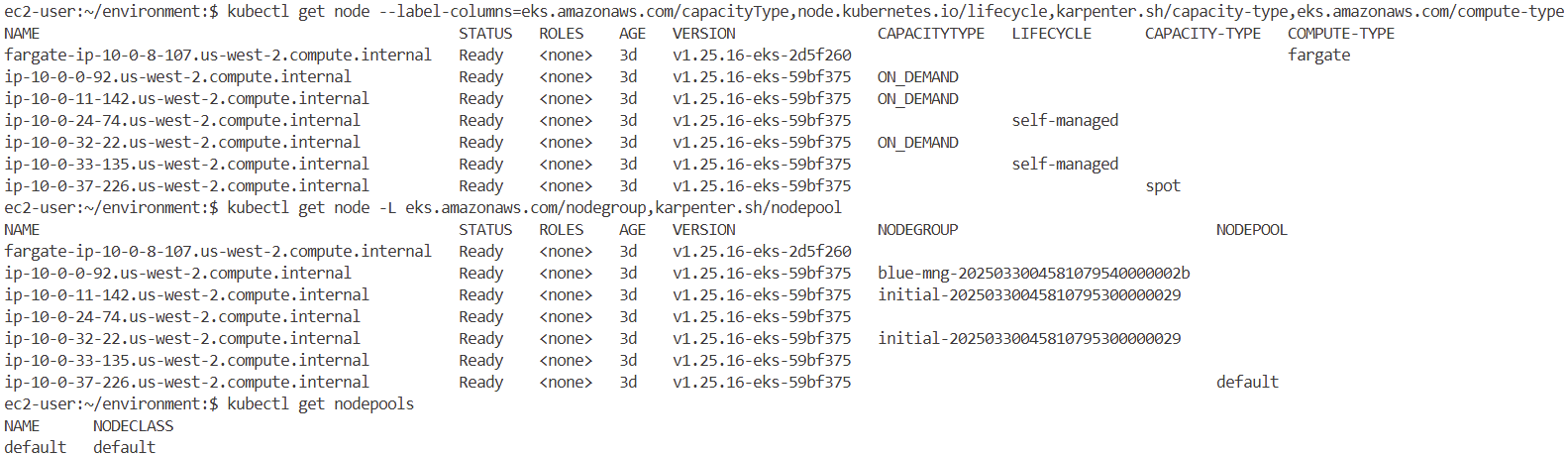
kubectl get node --label-columns=eks.amazonaws.com/capacityType,node.kubernetes.io/lifecycle,karpenter.sh/capacity-type,eks.amazonaws.com/compute-type
kubectl get node -L eks.amazonaws.com/nodegroup,karpenter.sh/nodepool
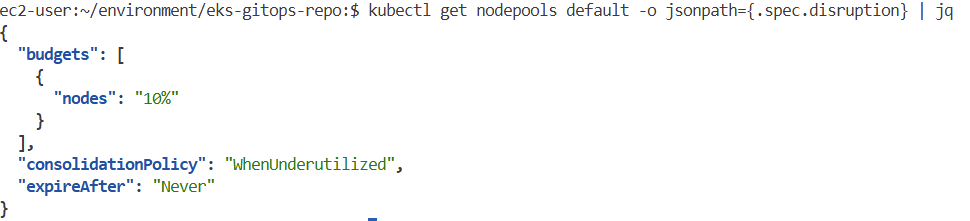
kubectl get nodepools
kubectl get nodeclaims -o yaml
kubectl get nodeclaims
kubectl get node --label-columns=node.kubernetes.io/instance-type,kubernetes.io/arch,kubernetes.io/os,topology.kubernetes.io/zone
#
kubectl cluster-info
#
kubectl get nodes -owide


#
kubectl get crd
NAME CREATED AT
applications.argoproj.io 2025-03-30T05:02:54Z
applicationsets.argoproj.io 2025-03-30T05:02:54Z
appprojects.argoproj.io 2025-03-30T05:02:54Z
cninodes.vpcresources.k8s.aws 2025-03-30T04:53:42Z
ec2nodeclasses.karpenter.k8s.aws 2025-03-30T05:03:20Z
eniconfigs.crd.k8s.amazonaws.com 2025-03-30T04:55:33Z
ingressclassparams.elbv2.k8s.aws 2025-03-30T05:03:20Z
nodeclaims.karpenter.sh 2025-03-30T05:03:20Z
nodepools.karpenter.sh 2025-03-30T05:03:20Z
policyendpoints.networking.k8s.aws 2025-03-30T04:53:42Z
securitygrouppolicies.vpcresources.k8s.aws 2025-03-30T04:53:42Z
targetgroupbindings.elbv2.k8s.aws 2025-03-30T05:03:20Z
helm list -A
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
argo-cd argocd 1 2025-03-30 05:02:52.349490586 +0000 UTC deployed argo-cd-5.55.0 v2.10.0
aws-efs-csi-driver kube-system 1 2025-03-30 05:03:21.744199535 +0000 UTC deployed aws-efs-csi-driver-2.5.6 1.7.6
aws-load-balancer-controller kube-system 1 2025-03-30 05:03:23.03590132 +0000 UTC deployed aws-load-balancer-controller-1.7.1 v2.7.1
karpenter karpenter 1 2025-03-30 05:03:20.948106493 +0000 UTC deployed karpenter-0.37.0 0.37.0
metrics-server kube-system 1 2025-03-30 05:02:52.346499847 +0000 UTC deployed metrics-server-3.12.0 0.7.0
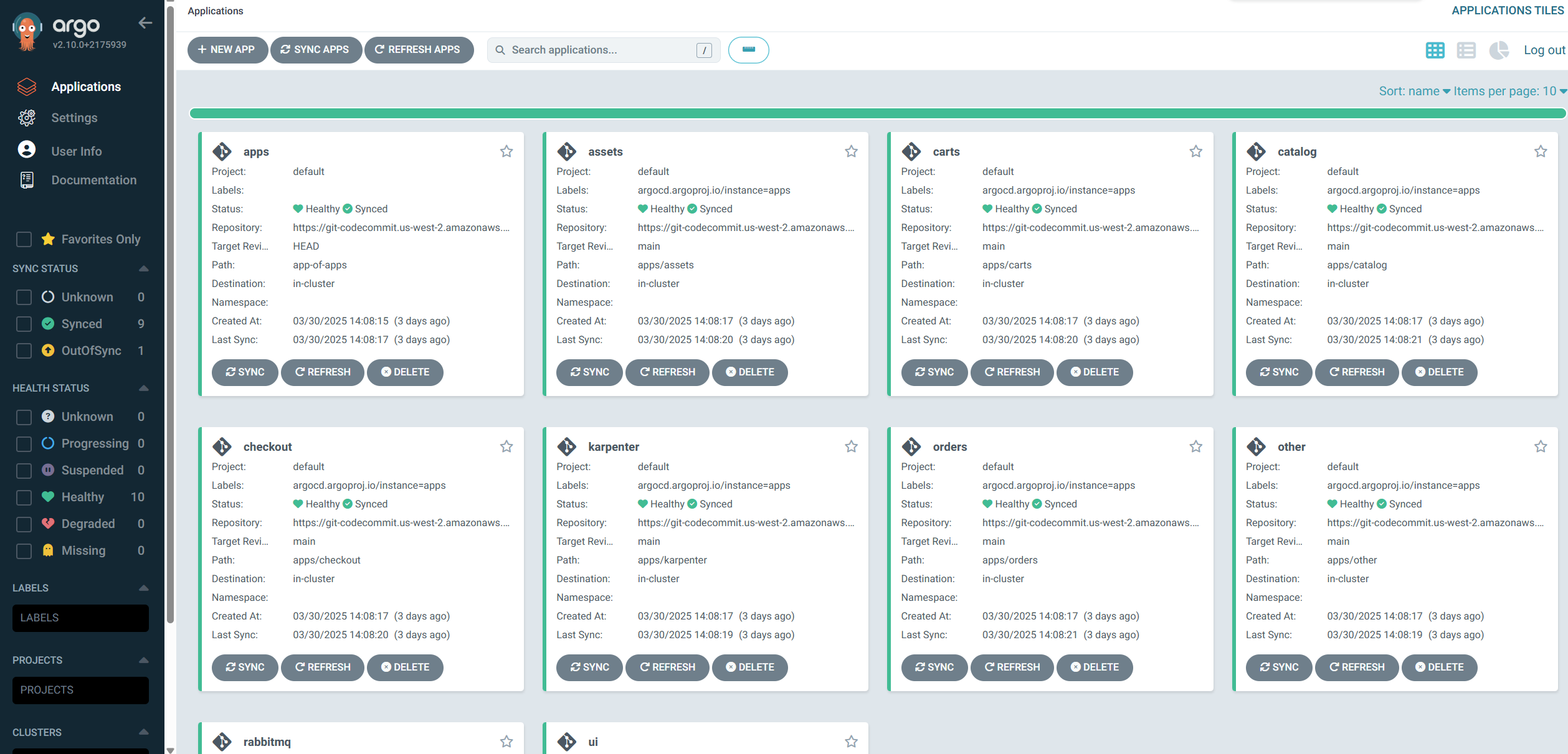
kubectl get applications -n argocd
NAME SYNC STATUS HEALTH STATUS
apps Synced Healthy
assets Synced Healthy
carts Synced Healthy
catalog Synced Healthy
checkout Synced Healthy
karpenter Synced Healthy
orders Synced Healthy
other Synced Healthy
rabbitmq Synced Healthy
ui OutOfSync Healthy
#
kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
argocd argo-cd-argocd-application-controller-0 1/1 Running 0 3d
argocd argo-cd-argocd-applicationset-controller-74d9c9c5c7-cd7cg 1/1 Running 0 3d
argocd argo-cd-argocd-dex-server-6dbbd57479-7k4nl 1/1 Running 0 3d
argocd argo-cd-argocd-notifications-controller-fb4b954d5-kcjnj 1/1 Running 0 3d
argocd argo-cd-argocd-redis-76b4c599dc-n6pqq 1/1 Running 0 3d
argocd argo-cd-argocd-repo-server-6b777b579d-n7fpj 1/1 Running 0 3d
argocd argo-cd-argocd-server-86bdbd7b89-jpvv5 1/1 Running 0 3d
assets assets-7ccc84cb4d-sqkhd 1/1 Running 0 3d
carts carts-7ddbc698d8-6trg7 1/1 Running 0 3d
carts carts-dynamodb-6594f86bb9-9jstd 1/1 Running 0 3d
catalog catalog-857f89d57d-2nhfv 1/1 Running 4 (3d ago) 3d
catalog catalog-mysql-0 1/1 Running 0 3d
checkout checkout-558f7777c-vnp7f 1/1 Running 0 3d
checkout checkout-redis-f54bf7cb5-84h9x 1/1 Running 0 3d
karpenter karpenter-5796f8578c-fl4kf 1/1 Running 1 (3d ago) 3d
karpenter karpenter-5796f8578c-vs9nf 1/1 Running 2 (3d ago) 3d
kube-system aws-load-balancer-controller-56779447c9-8bn5g 1/1 Running 0 3d
kube-system aws-load-balancer-controller-56779447c9-zfctt 1/1 Running 0 3d
kube-system aws-node-6hfwl 2/2 Running 0 3d
kube-system aws-node-8n64l 2/2 Running 0 3d
kube-system aws-node-h648j 2/2 Running 0 3d
kube-system aws-node-qsrbq 2/2 Running 0 3d
kube-system aws-node-xfksl 2/2 Running 0 3d
kube-system aws-node-xwdpg 2/2 Running 0 3d
kube-system coredns-98f76fbc4-c4d77 1/1 Running 0 3d
kube-system coredns-98f76fbc4-jj6ww 1/1 Running 0 3d
kube-system ebs-csi-controller-6b575b5f4d-hwf9n 6/6 Running 0 3d
kube-system ebs-csi-controller-6b575b5f4d-wh65k 6/6 Running 0 3d
kube-system ebs-csi-node-5rn59 3/3 Running 0 3d
kube-system ebs-csi-node-7tcdm 3/3 Running 0 3d
kube-system ebs-csi-node-9wqr5 3/3 Running 0 3d
kube-system ebs-csi-node-kngm4 3/3 Running 0 3d
kube-system ebs-csi-node-vhrgt 3/3 Running 0 3d
kube-system ebs-csi-node-xtmkr 3/3 Running 0 3d
kube-system efs-csi-controller-5d74ddd947-hztmw 3/3 Running 0 3d
kube-system efs-csi-controller-5d74ddd947-s4qnp 3/3 Running 0 3d
kube-system efs-csi-node-7mlhl 3/3 Running 0 3d
kube-system efs-csi-node-8zdwx 3/3 Running 0 3d
kube-system efs-csi-node-b7zcb 3/3 Running 0 3d
kube-system efs-csi-node-hmstm 3/3 Running 0 3d
kube-system efs-csi-node-mxbns 3/3 Running 0 3d
kube-system efs-csi-node-zc2xw 3/3 Running 0 3d
kube-system kube-proxy-4vb4k 1/1 Running 0 3d
kube-system kube-proxy-6gwgs 1/1 Running 0 3d
kube-system kube-proxy-mpnhv 1/1 Running 0 3d
kube-system kube-proxy-rdmbv 1/1 Running 0 3d
kube-system kube-proxy-rp9wq 1/1 Running 0 3d
kube-system kube-proxy-xz5bl 1/1 Running 0 3d
kube-system metrics-server-785cd745cd-c95f5 1/1 Running 0 3d
orders orders-5b97745747-hr6kl 1/1 Running 2 (3d ago) 3d
orders orders-mysql-b9b997d9d-snktb 1/1 Running 0 3d
rabbitmq rabbitmq-0 1/1 Running 0 3d
ui ui-5dfb7d65fc-p6tw9 1/1 Running 0 3d
#
kubectl get pdb -A
NAMESPACE NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
karpenter karpenter N/A 1 1 3d
kube-system aws-load-balancer-controller N/A 1 1 3d
kube-system coredns N/A 1 1 3d
kube-system ebs-csi-controller N/A 1 1 3d
#
kubectl get svc -n argocd argo-cd-argocd-server
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
argo-cd-argocd-server LoadBalancer 172.20.218.193 k8s-argocd-argocdar-3a4a893925-87533b55225f93d5.elb.us-west-2.amazonaws.com 80:32459/TCP,443:30295/TCP 3d
kubectl get targetgroupbindings -n argocd
NAME SERVICE-NAME SERVICE-PORT TARGET-TYPE AGE
k8s-argocd-argocdar-13acfbe2d7 argo-cd-argocd-server 80 ip 3d
k8s-argocd-argocdar-96de8d130e argo-cd-argocd-server 443 ip 3d# 노드에 taint 정보 확인
kubectl get nodes -o custom-columns='NODE:.metadata.name,TAINTS:.spec.taints[*].key,VALUES:.spec.taints[*].value,EFFECTS:.spec.taints[*].effect'
NODE TAINTS VALUES EFFECTS
fargate-ip-10-0-8-107.us-west-2.compute.internal eks.amazonaws.com/compute-type fargate NoSchedule
ip-10-0-0-92.us-west-2.compute.internal dedicated OrdersApp NoSchedule
ip-10-0-11-142.us-west-2.compute.internal <none> <none> <none>
ip-10-0-24-74.us-west-2.compute.internal <none> <none> <none>
ip-10-0-32-22.us-west-2.compute.internal <none> <none> <none>
ip-10-0-33-135.us-west-2.compute.internal <none> <none> <none>
ip-10-0-37-226.us-west-2.compute.internal dedicated CheckoutApp NoSchedule
#
kubectl get node -L eks.amazonaws.com/nodegroup,karpenter.sh/nodepool
NAME STATUS ROLES AGE VERSION NODEGROUP NODEPOOL
fargate-ip-10-0-8-107.us-west-2.compute.internal Ready <none> 3d v1.25.16-eks-2d5f260
ip-10-0-0-92.us-west-2.compute.internal Ready <none> 3d v1.25.16-eks-59bf375 blue-mng-2025033004581079540000002b
ip-10-0-11-142.us-west-2.compute.internal Ready <none> 3d v1.25.16-eks-59bf375 initial-20250330045810795300000029
ip-10-0-24-74.us-west-2.compute.internal Ready <none> 3d v1.25.16-eks-59bf375
ip-10-0-32-22.us-west-2.compute.internal Ready <none> 3d v1.25.16-eks-59bf375 initial-20250330045810795300000029
ip-10-0-33-135.us-west-2.compute.internal Ready <none> 3d v1.25.16-eks-59bf375
ip-10-0-37-226.us-west-2.compute.internal Ready <none> 3d v1.25.16-eks-59bf375 default
# 노드 별 label 확인
kubectl get nodes -o json | jq '.items[] | {name: .metadata.name, labels: .metadata.labels}'
{
"name": "fargate-ip-10-0-8-107.us-west-2.compute.internal",
"labels": {
"beta.kubernetes.io/arch": "amd64",
"beta.kubernetes.io/os": "linux",
"eks.amazonaws.com/compute-type": "fargate",
"failure-domain.beta.kubernetes.io/region": "us-west-2",
"failure-domain.beta.kubernetes.io/zone": "us-west-2a",
"kubernetes.io/arch": "amd64",
"kubernetes.io/hostname": "ip-10-0-8-107.us-west-2.compute.internal",
"kubernetes.io/os": "linux",
"topology.kubernetes.io/region": "us-west-2",
"topology.kubernetes.io/zone": "us-west-2a"
}
}
{
"name": "ip-10-0-0-92.us-west-2.compute.internal",
"labels": {
"beta.kubernetes.io/arch": "amd64",
"beta.kubernetes.io/instance-type": "m5.large",
"beta.kubernetes.io/os": "linux",
"eks.amazonaws.com/capacityType": "ON_DEMAND",
"eks.amazonaws.com/nodegroup": "blue-mng-2025033004581079540000002b",
"eks.amazonaws.com/nodegroup-image": "ami-0078a0f78fafda978",
"eks.amazonaws.com/sourceLaunchTemplateId": "lt-0593d8c7b7d9f340c",
"eks.amazonaws.com/sourceLaunchTemplateVersion": "1",
"failure-domain.beta.kubernetes.io/region": "us-west-2",
"failure-domain.beta.kubernetes.io/zone": "us-west-2a",
"k8s.io/cloud-provider-aws": "a94967527effcefb5f5829f529c0a1b9",
"kubernetes.io/arch": "amd64",
"kubernetes.io/hostname": "ip-10-0-0-92.us-west-2.compute.internal",
"kubernetes.io/os": "linux",
"node.kubernetes.io/instance-type": "m5.large",
"topology.ebs.csi.aws.com/zone": "us-west-2a",
"topology.kubernetes.io/region": "us-west-2",
"topology.kubernetes.io/zone": "us-west-2a",
"type": "OrdersMNG"
}
}
...
#
kubectl get sts -A
NAMESPACE NAME READY AGE
argocd argo-cd-argocd-application-controller 1/1 3d
catalog catalog-mysql 1/1 3d
rabbitmq rabbitmq 1/1 3d
#
kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
efs efs.csi.aws.com Delete Immediate true 3d
gp2 kubernetes.io/aws-ebs Delete WaitForFirstConsumer false 3d
gp3 (default) ebs.csi.aws.com Delete WaitForFirstConsumer true 3d
kubectl describe sc efs
...
Provisioner: efs.csi.aws.com
Parameters: basePath=/dynamic_provisioning,directoryPerms=755,ensureUniqueDirectory=false,fileSystemId=fs-0cc9ee2c4deaa3a5c,gidRangeEnd=200,gidRangeStart=100,provisioningMode=efs-ap,reuseAccessPoint=false,subPathPattern=${.PVC.namespace}/${.PVC.name}
AllowVolumeExpansion: True
...
#
kubectl get pv,pvc -A
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pvc-43f03bef-89ef-47a3-bb40-352c78a61528 4Gi RWO Delete Bound orders/order-mysql-pvc gp3 3d
persistentvolume/pvc-56e56d86-b252-435d-83c7-ff2a20ba7f3e 4Gi RWO Delete Bound catalog/catalog-mysql-pvc gp3 3d
persistentvolume/pvc-ed19ae6a-d346-441c-b77e-abab498bcb5a 4Gi RWO Delete Bound checkout/checkout-redis-pvc gp3 3d
NAMESPACE NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
catalog persistentvolumeclaim/catalog-mysql-pvc Bound pvc-56e56d86-b252-435d-83c7-ff2a20ba7f3e 4Gi RWO gp3 3d
checkout persistentvolumeclaim/checkout-redis-pvc Bound pvc-ed19ae6a-d346-441c-b77e-abab498bcb5a 4Gi RWO gp3 3d
orders persistentvolumeclaim/order-mysql-pvc Bound pvc-43f03bef-89ef-47a3-bb40-352c78a61528 4Gi RWO gp3 3d#
aws eks list-access-entries --cluster-name $CLUSTER_NAME
{
"accessEntries": [
"arn:aws:iam::27----------:role/aws-service-role/eks.amazonaws.com/AWSServiceRoleForAmazonEKS",
"arn:aws:iam::27----------:role/blue-mng-eks-node-group-2025033004475658620000000f",
"arn:aws:iam::27----------:role/default-selfmng-node-group-2025033004475644460000000e",
"arn:aws:iam::27----------:role/fp-profile-20250330045805300500000021",
"arn:aws:iam::27----------:role/initial-eks-node-group-20250330044756940000000010",
"arn:aws:iam::27----------:role/karpenter-eksworkshop-eksctl",
"arn:aws:iam::27----------:role/workshop-stack-ekstfcodebuildStackDeployProjectRole-AxqP4Tgyfdwu"
]
}
#
eksctl get iamidentitymapping --cluster $CLUSTER_NAME
ARN USERNAME GROUPS ACCOUNT
arn:aws:iam::279109813637:role/WSParticipantRole admin system:masters
arn:aws:iam::279109813637:role/blue-mng-eks-node-group-2025033004475658620000000f system:node:{{EC2PrivateDNSName}} system:bootstrappers,system:nodes
arn:aws:iam::279109813637:role/fp-profile-20250330045805300500000021 system:node:{{SessionName}} system:bootstrappers,system:nodes,system:node-proxier
arn:aws:iam::279109813637:role/initial-eks-node-group-20250330044756940000000010 system:node:{{EC2PrivateDNSName}} system:bootstrappers,system:nodes
arn:aws:iam::279109813637:role/workshop-stack-IdeIdeRoleD654ADD4-JUopYyQ1gHs5 admin system:masters
#
kubectl describe cm -n kube-system aws-auth
====
mapRoles:
----
- groups:
- system:bootstrappers
- system:nodes
- system:node-proxier
rolearn: arn:aws:iam::279109813637:role/fp-profile-20250330045805300500000021
username: system:node:{{SessionName}}
- groups:
- system:bootstrappers
- system:nodes
rolearn: arn:aws:iam::279109813637:role/initial-eks-node-group-20250330044756940000000010
username: system:node:{{EC2PrivateDNSName}}
- groups:
- system:bootstrappers
- system:nodes
rolearn: arn:aws:iam::279109813637:role/blue-mng-eks-node-group-2025033004475658620000000f
username: system:node:{{EC2PrivateDNSName}}
- groups:
- system:masters
rolearn: arn:aws:iam::279109813637:role/WSParticipantRole
username: admin
- groups:
- system:masters
rolearn: arn:aws:iam::279109813637:role/workshop-stack-IdeIdeRoleD654ADD4-JUopYyQ1gHs5
username: admin
mapUsers:
----
# IRSA : karpenter, alb-controller, ebs-csi-driver, aws-efs-csi-driver 4곳에서 사용
eksctl get iamserviceaccount --cluster $CLUSTER_NAME
kubectl describe sa -A | grep role-arn
Annotations: eks.amazonaws.com/role-arn: arn:aws:iam::27----------:role/karpenter-2025033005031961750000003a
Annotations: eks.amazonaws.com/role-arn: arn:aws:iam::27----------:role/alb-controller-20250330050319611100000039
Annotations: eks.amazonaws.com/role-arn: arn:aws:iam::27----------:role/eksworkshop-eksctl-ebs-csi-driver-2025033004573620380000001d
Annotations: eks.amazonaws.com/role-arn: arn:aws:iam::27----------:role/aws-efs-csi-driver-2025033005031963620000003f
Annotations: eks.amazonaws.com/role-arn: arn:aws:iam::27----------:role/aws-efs-csi-driver-2025033005031963620000003f
# pod identity 없음
eksctl get podidentityassociation --cluster $CLUSTER_NAME
# EKS API Endpoint
aws eks describe-cluster --name $CLUSTER_NAME | jq -r .cluster.endpoint | cut -d '/' -f 3
B2D495-----------A.gr7.us-west-2.eks.amazonaws.com
dig +short $APIDNS
44.231.29.4
44.226.184.195
# OIDC
aws eks describe-cluster --name $CLUSTER_NAME --query cluster.identity.oidc.issuer --output text
https://oidc.eks.us-west-2.amazonaws.com/id/B2D495685BE59970E97D3E048CE6285A
aws iam list-open-id-connect-providers | jq
{
"OpenIDConnectProviderList": [
{
"Arn": "arn:aws:iam::27----------:oidc-provider/oidc.eks.us-west-2.amazonaws.com/id/B2D495685BE59970E97D3E048CE6285A"
}
]
}
AWS 관리 콘솔 접속: EKS, EC2, VPC 등 확인
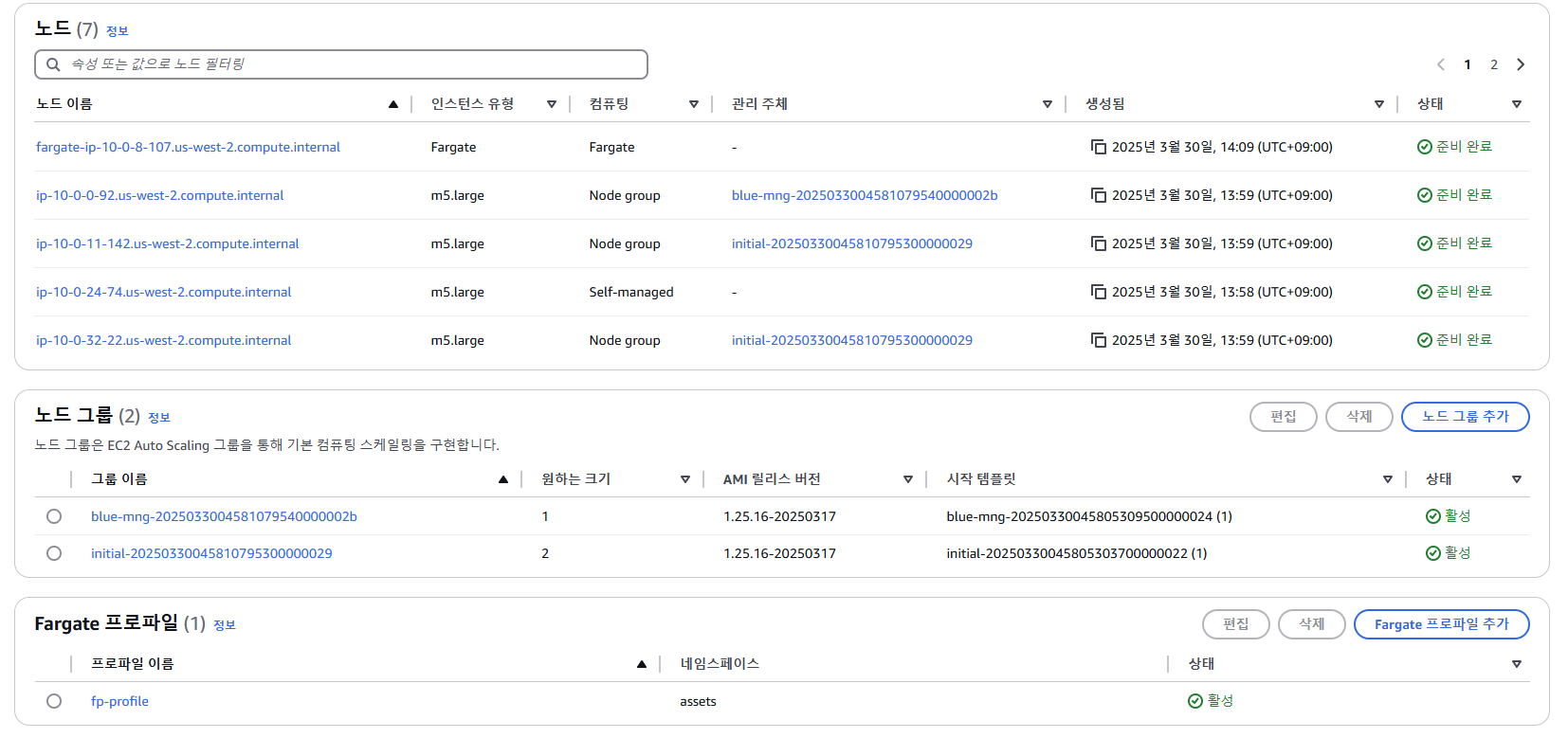
- EKS - Compute
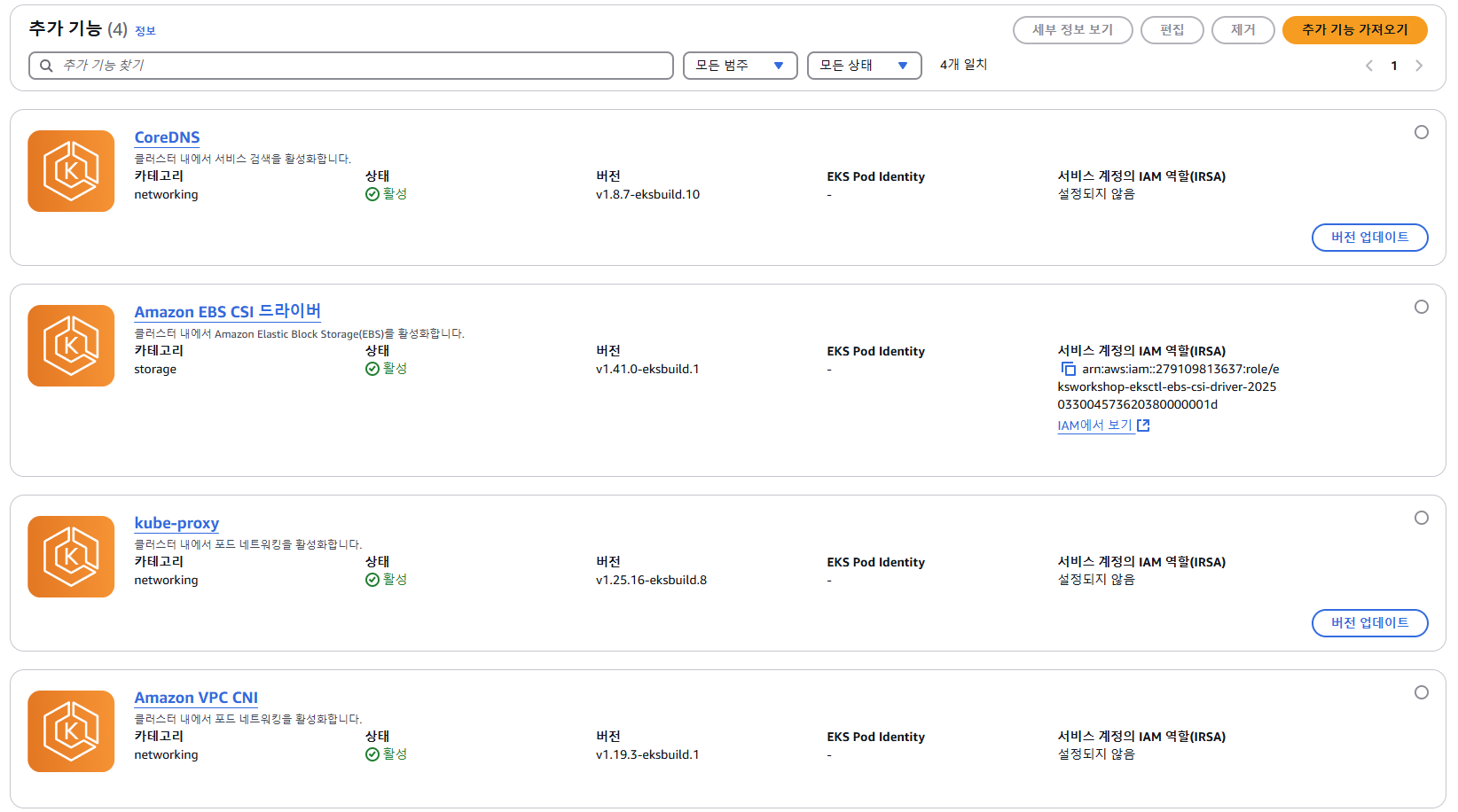
- EKS - Addon
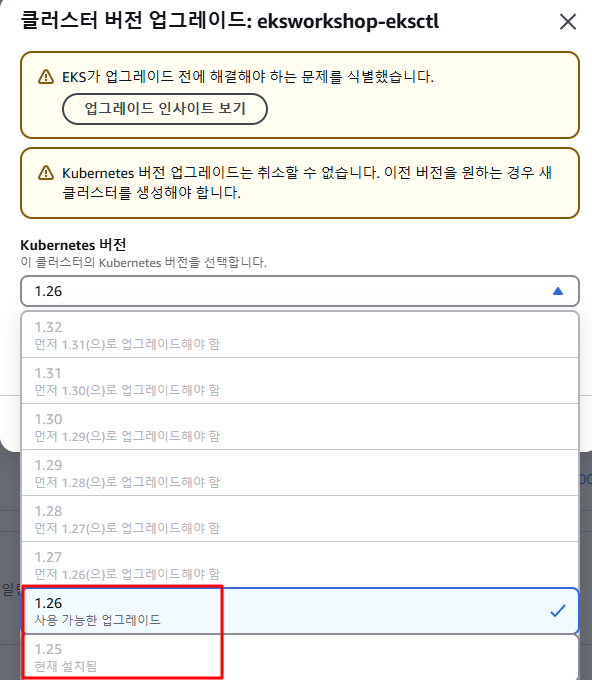
- EKS - Upgrade Version : 상위 1개 마이너 버전 업그레이드만 가능(확인만 진행하고 실행X)
- 버전 여러개를 한번에 건너뛰고 업그레이드 불가능 함.
- EKS - Dashboard - Cluster insights : Deprecated APIs remove in Kubernetes 1.26 클릭 상세 확인

- EC2 - LB : ArgoCD 외부 접속용 NLB 확인

- EC2 - ASG : 3개의 ASG 확인 - blug-mng 관리 노드는 AZ1 곳만 사용 중(us-west-2a)

추가 편의 툴 설치
- kube-ops-view
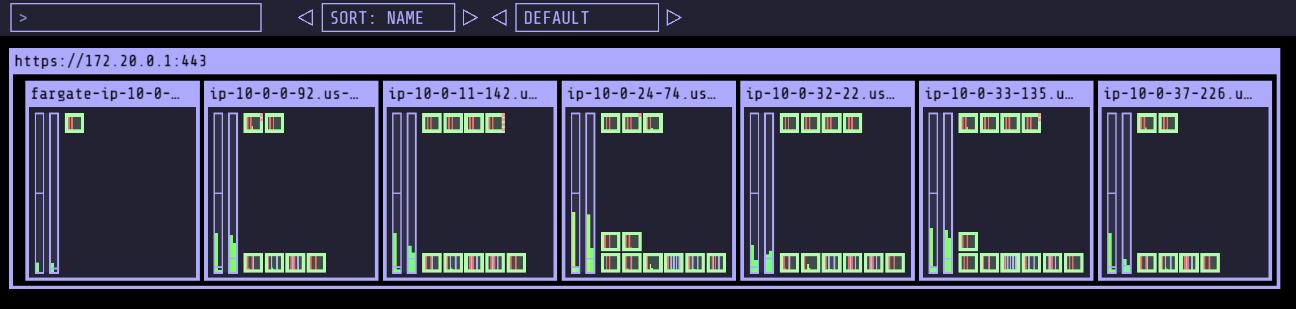
- krew

- eks-node-view
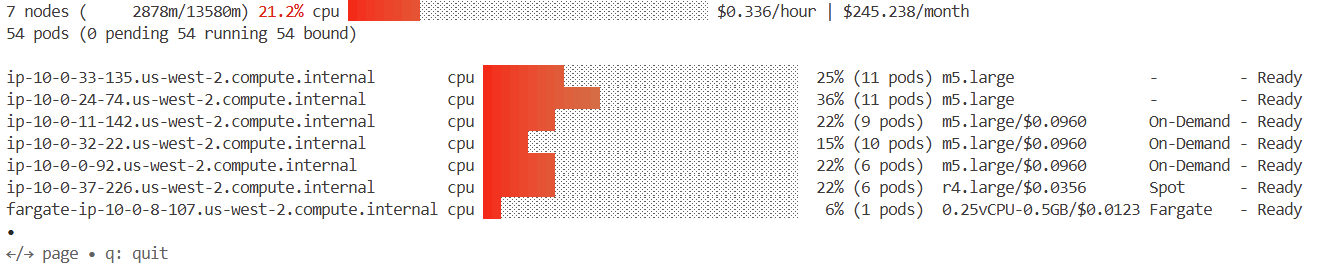
- k9s

- argoCD
Preparing for Cluster Upgrades : 업그레이드 전 준비
- 준비
- 클러스터 업그레이드를 시작하기 전에 다음 요구 사항을 확인하세요.
- Amazon EKS에서는 클러스터를 생성할 때 지정한 서브넷에서 사용 가능한 IP 주소를 최대 5개까지 필요로 합니다 .
- 클러스터의 AWS Identity and Access Management(IAM) 역할과 보안 그룹 이 AWS 계정에 있어야 합니다 .
- 비밀 암호화를 활성화하는 경우 클러스터 IAM 역할에 AWS Key Management Service(AWS KMS) 키 권한이 있어야 합니다 .
- 클러스터 업그레이드를 시작하기 전에 다음 요구 사항을 확인하세요.
- 업그레이드 워크플로
- Amazon EKS 및 Kubernetes 버전에 대한 주요 업데이트 식별 Identify
- 사용 중단 정책 이해 및 적절한 매니페스트 리팩토링 Understand , Refactor
- 올바른 업그레이드 전략을 사용하여 EKS 제어 평면 및 데이터 평면 업데이트 Update
- 마지막으로 다운스트림 애드온 종속성 업그레이드

EKS Upgrade Insights
- Amazon EKS 클러스터 인사이트는 Amazon EKS 및 Kubernetes 모범 사례를 따르는 데 도움이 되는 권장 사항을 제공합니다.
- 모든 Amazon EKS 클러스터는 Amazon EKS가 선별한 인사이트 목록에 대해 자동으로 반복적으로 검사를 받습니다.
- 이러한 인사이트 검사는 Amazon EKS에서 완전히 관리하며 모든 결과를 해결하는 방법에 대한 권장 사항을 제공합니다.
- Cluster 인사이트를 활용하면 최신 Kubernetes 버전으로 업그레이드하는 데 드는 노력을 최소화할 수 있습니다.
- 매일 클러스터 감사 로그를 스캔하여 사용되지 않는 리소스를 찾고 EKS 콘솔에 결과를 표시하거나 API 또는 CLI를 통해 프로그래밍 방식으로 검색할 수 있습니다.
- Amazon EKS는 Kubernetes 버전 업그레이드 준비와 관련된 insight만 출력.
- 클러스터 인사이트는 주기적으로 업데이트됩니다. 클러스터 인사이트를 수동으로 새로 고칠 수 없습니다. 클러스터 문제를 해결하면 클러스터 인사이트가 업데이트되는 데 시간이 걸립니다.
Each insight includes
- 권장 사항: 문제를 해결하기 위한 단계.
- 링크: 릴리스 노트, 블로그 게시물과 같은 추가 정보입니다.
- 리소스 목록: 심각도를 반영하는 상태(통과, 경고, 오류, 알 수 없음)가 있는 Kubernetes 리소스 유형(예: CronJobs)입니다.
- 오류: 다음 마이너 버전에서 API에 대한 호출이 제거되었습니다. 업그레이드 후 업그레이드가 실패합니다.
- 경고: 임박한 문제이지만 즉각적인 조치가 필요하지 않습니다(2개 이상 릴리스된 버전에서 지원 중단).
- 알 수 없음: 백엔드 처리 오류.
- 전체 상태: 인사이트의 모든 리소스 중에서 가장 높은 심각도 상태입니다. 이를 통해 업그레이드하기 전에 클러스터에 수정이 필요한지 빠르게 확인할 수 있습니다.
In-place Cluster Upgrade : 1.25 → 1.26
업그레이드 단계
- 클러스터 제어 평면 업그레이드
- Kubernetes 애드온 및 사용자 정의 컨트롤러를 업데이트하세요.
- 클러스터의 노드를 업그레이드하세요
1. Control Plane Upgrade
- Amazon EKS에서 클러스터를 실행하는 가장 큰 이점 중 하나는 클러스터 제어 평면의 업그레이드가 단일 완전 자동화된 작업이라는 것입니다. 업그레이드하는 동안 현재 제어 평면 구성 요소는 파란색/녹색 방식으로 업그레이드됩니다. 문제가 발생하면 업그레이드가 롤백되고 애플리케이션은 계속 작동하고 사용 가능합니다.
- 인플레이스 업그레이드는 다음으로 높은 Kubernetes 마이너 버전까지 점진적으로 진행되므로 현재 버전과 대상 버전 사이에 여러 릴리스가 있는 경우 순서대로 각 릴리스를 거쳐야 합니다. 다양한 요소를 고려하고 특정 요구 사항과 제약 조건에 가장 적합한 접근 방식을 평가하는 것이 중요합니다.
제어 평면을 업그레이드하기 전의 기본 Amazon EKS 요구 사항
- Amazon EKS는 클러스터를 업데이트하기 위해 클러스터를 생성할 때 지정한 서브넷에서 최대 5개의 사용 가능한 IP 주소가 필요합니다. IP를 사용할 수 없는 경우 버전 업데이트를 수행하기 전에 "UpdateClusterConfiguration" API를 사용하여 클러스터 구성을 업데이트하여 새 클러스터 서브넷을 포함하거나 기존 VPC CIDR 블록의 IP 주소가 부족하면 추가 CIDR 블록을 연결하는 것을 고려하세요.
- 제어 평면 IAM 역할은 필요한 권한이 있는 계정에 있어야 합니다.
- 클러스터에 비밀 암호화가 활성화된 경우 클러스터 IAM 역할에 AWS Key Management Service(AWS KMS) 키를 사용할 수 있는 권한이 있는지 확인해야 합니다.
Terraform을 사용한 클러스터 업그레이드
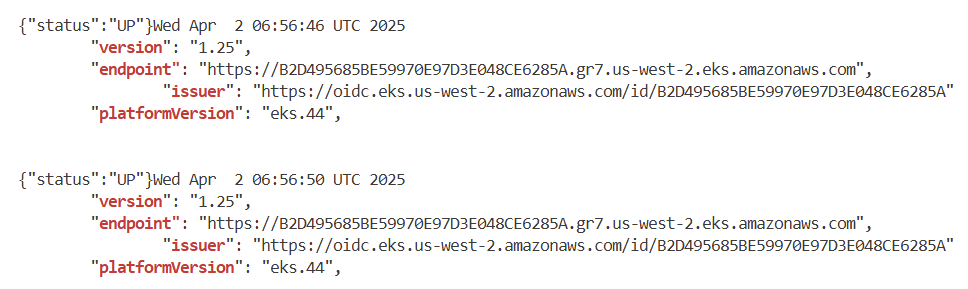
실습
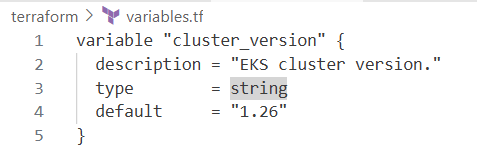
variable.tf의 cluster_version 변수를 1.25에서 1.26으로 변경하고 terraform plan을 실행
# 기본 정보
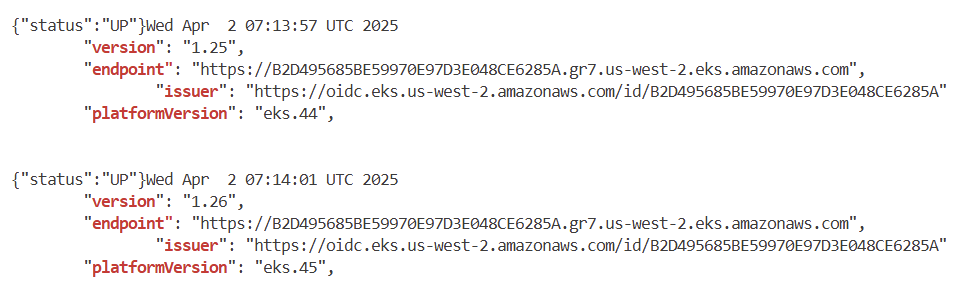
aws eks describe-cluster --name $EKS_CLUSTER_NAME | egrep 'version|endpoint"|issuer|platformVersion'
# 클러스터 버전을 변경하면 테라폼 계획에 표시된 것처럼, 관리 노드 그룹에 대한 특정 버전이나 AMI가 테라폼 파일에 정의되지 않은 경우,
# eks 클러스터 제어 평면과 관리 노드 그룹 및 애드온과 같은 관련 리소스를 업데이트하게 됩니다.
# 이 계획을 적용하여 제어 평면 버전을 업데이트해 보겠습니다.
terraform apply -auto-approve # 10분 소요
# eks control plane 1.26 업글 확인
aws eks describe-cluster --name $EKS_CLUSTER_NAME | jq
...
"version": "1.26",
# endpoint, issuer, platformVersion 동일 => IRSA 를 사용하는 4개의 App 동작에 문제 없음!
aws eks describe-cluster --name $EKS_CLUSTER_NAME | egrep 'version|endpoint"|issuer|platformVersion'
# 파드 컨테이너 이미지 버전 모두 동일
kubectl get pods --all-namespaces -o jsonpath="{.items[*].spec.containers[*].image}" | tr -s '[[:space:]]' '\n' | sort | uniq -c > 1.26.txt
kubectl get pods --all-namespaces -o jsonpath="{.items[*].spec.containers[*].image}" | tr -s '[[:space:]]' '\n' | sort | uniq -c
diff 1.26.txt 1.25.txt # 동일함
# 파드 AGE 정보 확인 : 재생성된 파드 없음!
kubectl get pod -A
...

2. Addon 업그레이드
- EKS 업그레이드의 일부로 클러스터에 설치된 애드온을 업그레이드해야 합니다. 애드온은 K8s 애플리케이션에 지원 운영 기능을 제공하는 소프트웨어로, 네트워킹, 컴퓨팅 및 스토리지를 위해 클러스터가 기본 AWS 리소스와 상호 작용할 수 있도록 하는 관찰 에이전트 또는 Kubernetes 드라이버와 같은 소프트웨어가 포함됩니다. 애드온 소프트웨어는 일반적으로 Kubernetes 커뮤니티, AWS와 같은 클라우드 공급자 또는 타사 공급업체에서 빌드하고 유지 관리합니다.
addons.tf아래에 표시된 대로 파일에 업데이트
실습
# 반복 접속 : 아래 coredns, kube-proxy addon 업그레이드 시 ui 무중단 통신 확인!
aws eks update-kubeconfig --name eksworkshop-eksctl # 자신의 집 PC일 경우
kubectl get pod -n kube-system -l k8s-app=kube-dns
kubectl get pod -n kube-system -l k8s-app=kube-proxy
kubectl get pod -n kube-system -l 'k8s-app in (kube-dns, kube-proxy)'
while true; do curl -s $UI_WEB ; date; kubectl get pod -n kube-system -l 'k8s-app in (kube-dns, kube-proxy)'; echo ; sleep 2; done
#
cd ~/environment/terraform/
terraform plan -no-color | tee addon.txt
# 1분 정도 이내로 롤링 업데이트 완료!
terraform apply -auto-approve
#
kubectl get pod -n kube-system -l 'k8s-app in (kube-dns, kube-proxy)'
#
kubectl get pods --all-namespaces -o jsonpath="{.items[*].spec.containers[*].image}" | tr -s '[[:space:]]' '\n' | sort | uniq -c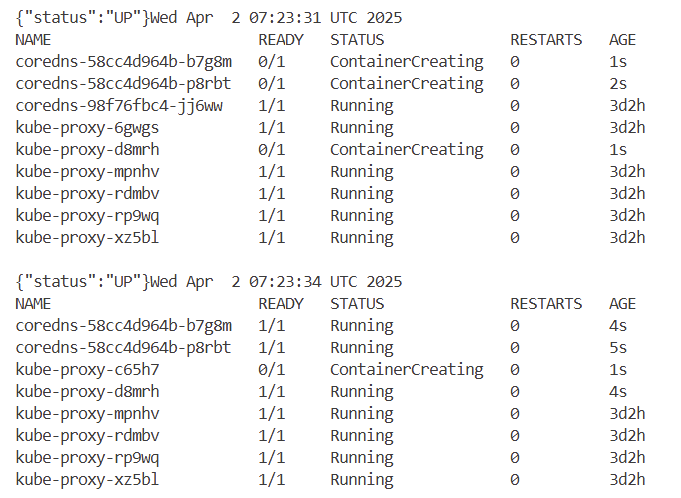

3. [데이터부 - 관리형노드그룹] 업그레이드
- 관리형 노드 그룹 : 업그레이드 전략 - 기존 EKS 관리 노드 그룹 업데이드(인플레이스) vs 새로운 EKS 관리 노드 그룹으로 마이그레이션(블루-그린)
- Amazon EKS 관리형 노드 그룹은 Amazon EKS 클러스터의 노드(Amazon EC2 인스턴스) 프로비저닝 및 수명 주기 관리를 자동화합니다.
- Amazon EKS 관리형 노드 그룹을 사용하면 Kubernetes 애플리케이션을 실행하기 위한 컴퓨팅 용량을 제공하는 Amazon EC2 인스턴스를 별도로 프로비저닝하거나 등록할 필요가 없습니다. 단일 작업으로 클러스터에 대한 노드를 생성, 자동 업데이트 또는 종료할 수 있습니다. 노드 업데이트 및 종료는 노드를 자동으로 비워 애플리케이션이 계속 사용 가능한 상태를 유지하도록 합니다.
- 모든 관리 노드는 Amazon EKS에서 관리하는 Amazon EC2 Auto Scaling 그룹의 일부로 프로비저닝됩니다. 인스턴스와 Auto Scaling 그룹을 포함한 모든 리소스는 AWS 계정 내에서 실행됩니다. 각 노드 그룹은 사용자가 정의한 여러 가용성 영역에서 실행됩니다.
[인플레이스 업그레이드] In-Place Managed Node group Upgrade
- 관리 노드 그룹 업그레이드도 완전히 자동화되어 점진적인 롤링 업데이트로 구현됩니다.
- 새 노드는 EC2 자동 스케일링 그룹에 프로비저닝되고 클러스터에 합류하며, as old nodes는 cordoned, drained, and removed
- 기본적으로 새 노드는 최신 EKS 최적화 AMI(Amazon Machine Image) 또는 선택적으로 사용자 지정 AMI를 사용합니다.
- 참고로, 사용자 지정 AMI를 사용할 때는 업데이트된 이미지를 직접 만들어야 하므로 노드 그룹 업그레이드의 일환으로 업데이트된 Launch Template 버전이 필요합니다.
실습
eks 모듈인 eks_managed_node_groups 아래의 base.tf 에서 두 관리 노드 그룹의 구성 확인 가능
#
cat base.tf
...
eks_managed_node_group_defaults = {
cluster_version = var.mng_cluster_version
}
eks_managed_node_groups = { # 버전 명시가 없으면, 상단 default 버전 사용 -> variables.tf 확인
initial = {
instance_types = ["m5.large", "m6a.large", "m6i.large"]
min_size = 2
max_size = 10
desired_size = 2
update_config = {
max_unavailable_percentage = 35
}
}
blue-mng={
instance_types = ["m5.large", "m6a.large", "m6i.large"]
cluster_version = "1.25"
min_size = 1
max_size = 2
desired_size = 1
update_config = {
max_unavailable_percentage = 35
}
labels = {
type = "OrdersMNG"
}
subnet_ids = [module.vpc.private_subnets[0]]
taints = [
{
key = "dedicated"
value = "OrdersApp"
effect = "NO_SCHEDULE"
}
]
}
kubernetes 버전 1.25의 ami_id를 가져오고 variable.tf 파일의 변수 ami_id를 결과 값으로 대체
#
aws ec2 describe-instances --query "Reservations[*].Instances[*].[Tags[?Key=='Name'].Value | [0], ImageId]" --filters "Name=tag:Blueprint,Values=eksworkshop-eksctl" --output table
#
kubectl get node --label-columns=eks.amazonaws.com/capacityType,node.kubernetes.io/lifecycle,karpenter.sh/capacity-type,eks.amazonaws.com/compute-type
kubectl get node -L eks.amazonaws.com/nodegroup,karpenter.sh/nodepool
#
kubectl get node -L eks.amazonaws.com/nodegroup-image | grep ami
#
aws ssm get-parameter --name /aws/service/eks/optimized-ami/1.25/amazon-linux-2/recommended/image_id \

base.tf사용자 정의 관리 노드 그룹을 프로비저닝하려면 다음 코드를 추가
custom = {
instance_types = ["t3.medium"]
min_size = 1
max_size = 2
desired_size = 1
update_config = {
max_unavailable_percentage = 35
}
ami_id = try(var.ami_id)
enable_bootstrap_user_data = true
}# 모니터링
aws autoscaling describe-auto-scaling-groups --query 'AutoScalingGroups[*].AutoScalingGroupName' --output json | jq
kubectl get node -L eks.amazonaws.com/nodegroup
kubectl get node -L eks.amazonaws.com/nodegroup-image | grep ami
while true; do aws autoscaling describe-auto-scaling-groups --query 'AutoScalingGroups[*].AutoScalingGroupName' --output json | jq; echo ; kubectl get node -L eks.amazonaws.com/nodegroup; echo; date ; echo ; kubectl get node -L eks.amazonaws.com/nodegroup-image | grep ami; echo; sleep 1; echo; done
# 2분 정도 소요
terraform plan && terraform apply -auto-approve
#
while true; do aws autoscaling describe-auto-scaling-groups --query 'AutoScalingGroups[*].AutoScalingGroupName' --output json | jq; echo ; kubectl get node -L eks.amazonaws.com/nodegroup; echo; date ; echo ; kubectl get node -L eks.amazonaws.com/nodegroup-image | grep ami; echo; sleep 1; echo; done
#
kubectl describe node ip-10-0-7-46.us-west-2.compute.internal
kubectl get pod -A -owide | grep 10-0-7-46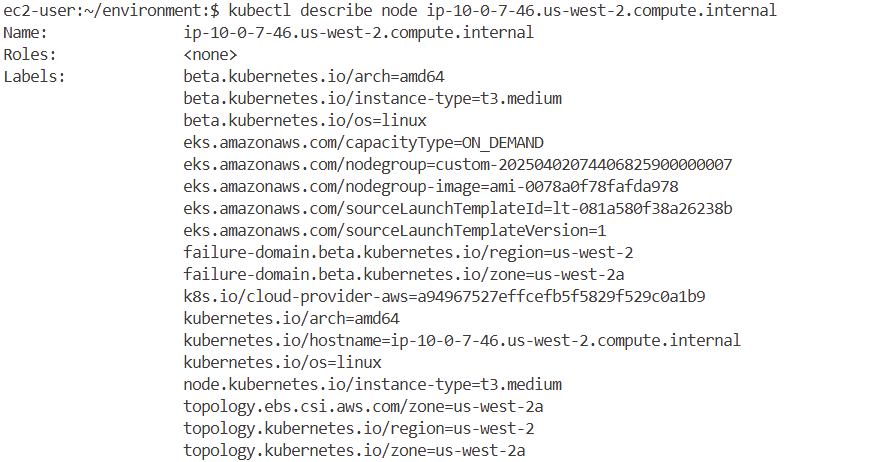


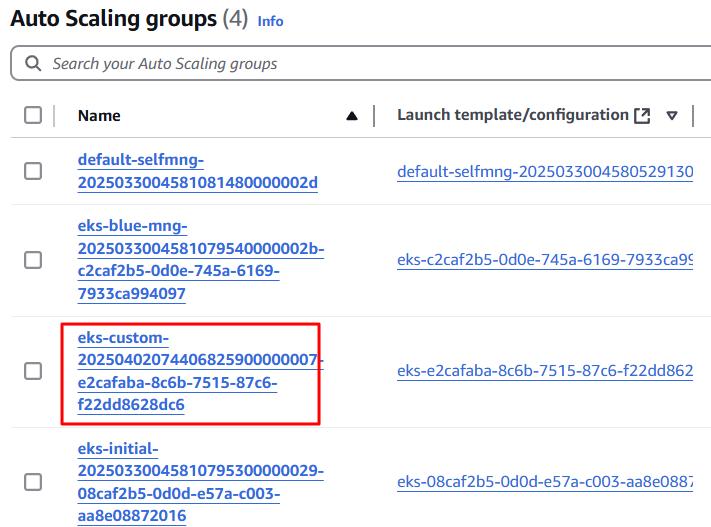
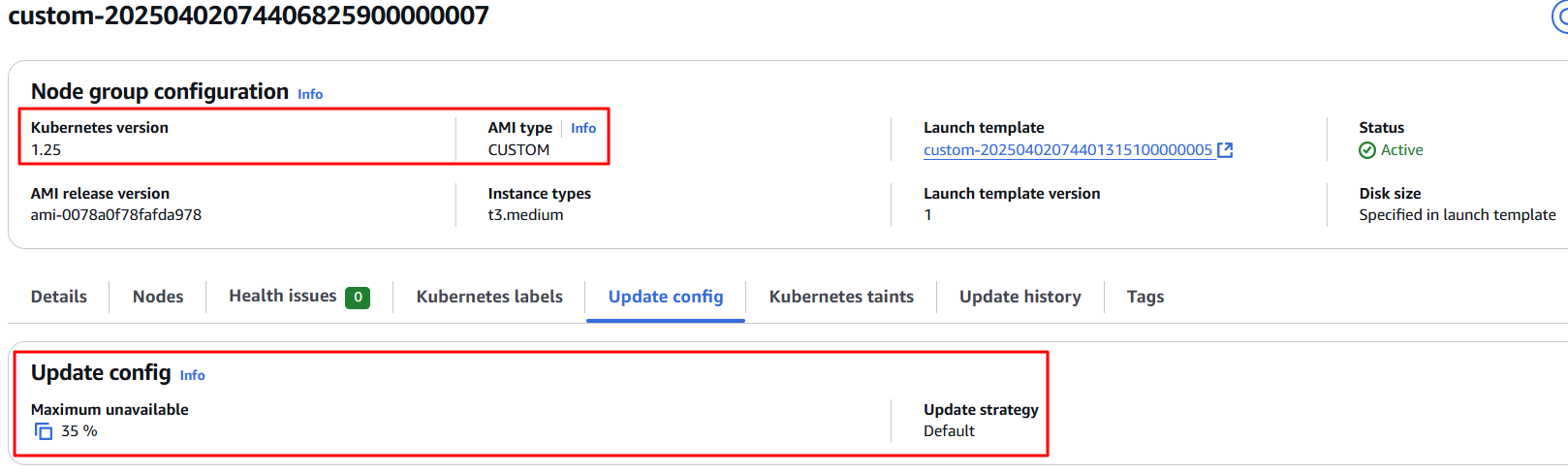
초기 관리 노드그룹에는 정의된 클러스터 버전이 없으며 기본적으로 eks_managed_node_group_defaults에 정의된 클러스터 버전을 사용하도록 설정
eks_managed_node_group_defaults 클러스터_버전의 값은 variable.tf 의 변수 mng_cluster_version에 정의돼 있음
variable.tf 에서 변수 mng_cluster_version을 "1.25"에서 "1.26"으로 변경하고 테라폼을 실행
#
terraform plan -no-color > plan-output.txt
# plan-output.txt 내용 확인
# module.eks.module.eks_managed_node_group["initial"].aws_eks_node_group.this[0] will be updated in-place
~ resource "aws_eks_node_group" "this" {
id = "eksworkshop-eksctl:initial-2025032502302076080000002c"
tags = {
"Blueprint" = "eksworkshop-eksctl"
"GithubRepo" = "github.com/aws-ia/terraform-aws-eks-blueprints"
"Name" = "initial"
"karpenter.sh/discovery" = "eksworkshop-eksctl"
}
~ version = "1.25" -> "1.26"
...
이 계획에 따라 initial managed node group은 1.26 버전으로 업그레이드되지만, custom managed nodegroup 을 프로비저닝하는 동안 특정 AMI를 정의했기 때문에 업그레이드 되지 않음.
따라서 커스텀 관리 노드 그룹과 같이 커스텀 AMI로 구성된 관리 노드 그룹이 있는 경우 업그레이드된 Kubernetes 버전에 커스텀 AMI를 제공하여 관리 노드 그룹을 업그레이드할 수 있음.
kubernetes 버전 1.26에 대해 ami_id를 검색한 후 variable.tf 에서 다음과 같은 변경 사항을 적용.
#
aws ssm get-parameter --name /aws/service/eks/optimized-ami/1.26/amazon-linux-2/recommended/image_id \
--region $AWS_REGION --query "Parameter.Value" --output text
- mng_cluster_version 변수를 1.25 -> 1.26 으로 변경
- ami_id 변수 변경
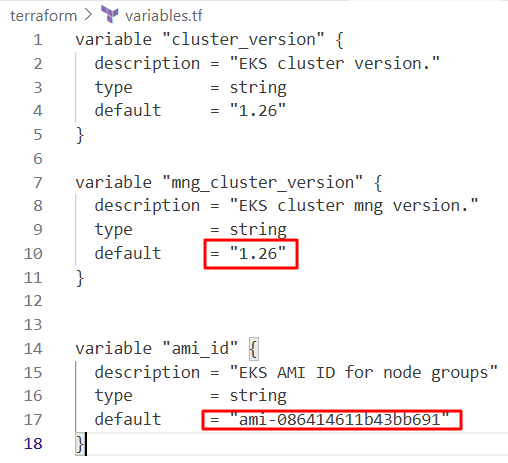
완료되면 Amazon EKS 콘솔에서 initial and custom manage node groups의 변경 사항 확인 가능
초기 및 맞춤형 관리 노드그룹 kubernetes 버전 1.26 확인

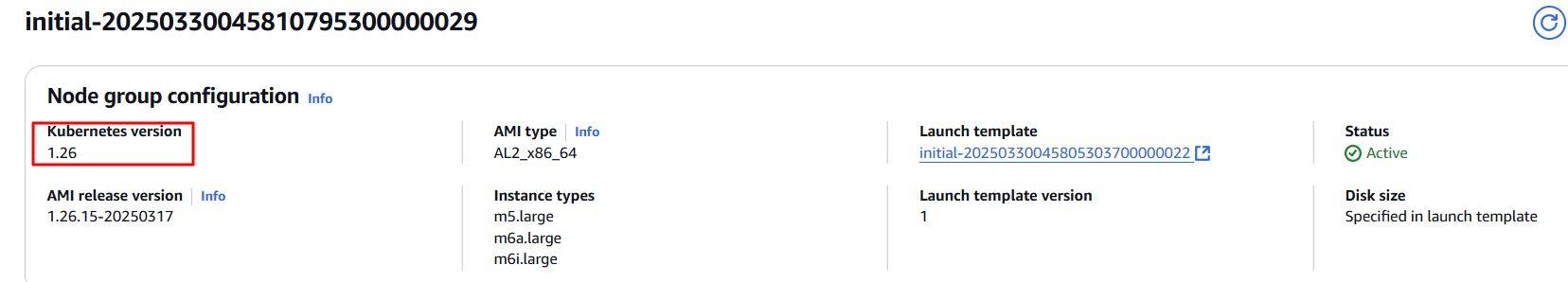
[블루-그린 업그레이드] Blue Green approach for Managed Node group Upgrade
- 관리 노드 그룹을 업데이트하기 위해 Blue / Green 전략을 사용할 수 있음
- 우리는 eks 제어 평면 버전을 업데이트한 후 새로운 관리 노드 그룹을 생성
- Blue-mng 관리 노드 그룹 구성은 노드 그룹에 할당된 노드들이 특정 테인트와 라벨을 가지고 있으며 하나의 특정 가용성 구역에 할당되도록 구성
- 상태 저장 워크로드를 위한 관리 노드 그룹은 가용 영역(AZ)별로 프로비저닝되어야 함.
#
kubectl get nodes -l type=OrdersMNG
# Check if the node have specific taints applied to it.
kubectl get nodes -l type=OrdersMNG -o jsonpath="{range .items[*]}{.metadata.name} {.spec.taints[?(@.effect=='NoSchedule')]}{\"\n\"}{end}"
# Check which pods are running on this node.
# Non-terminated Pods: in above output, kube-system pods and orders app pods running on this node.
kubectl describe node -l type=OrdersMNG
#
kubectl get pvc -n orders
#
cat eks-gitops-repo/apps/orders/deployment.yaml
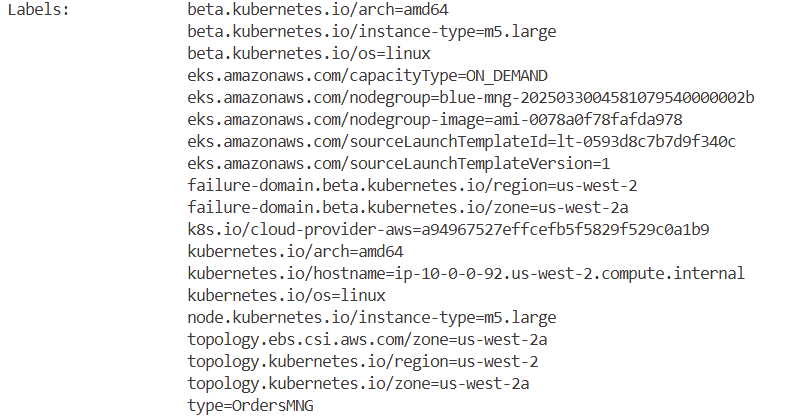

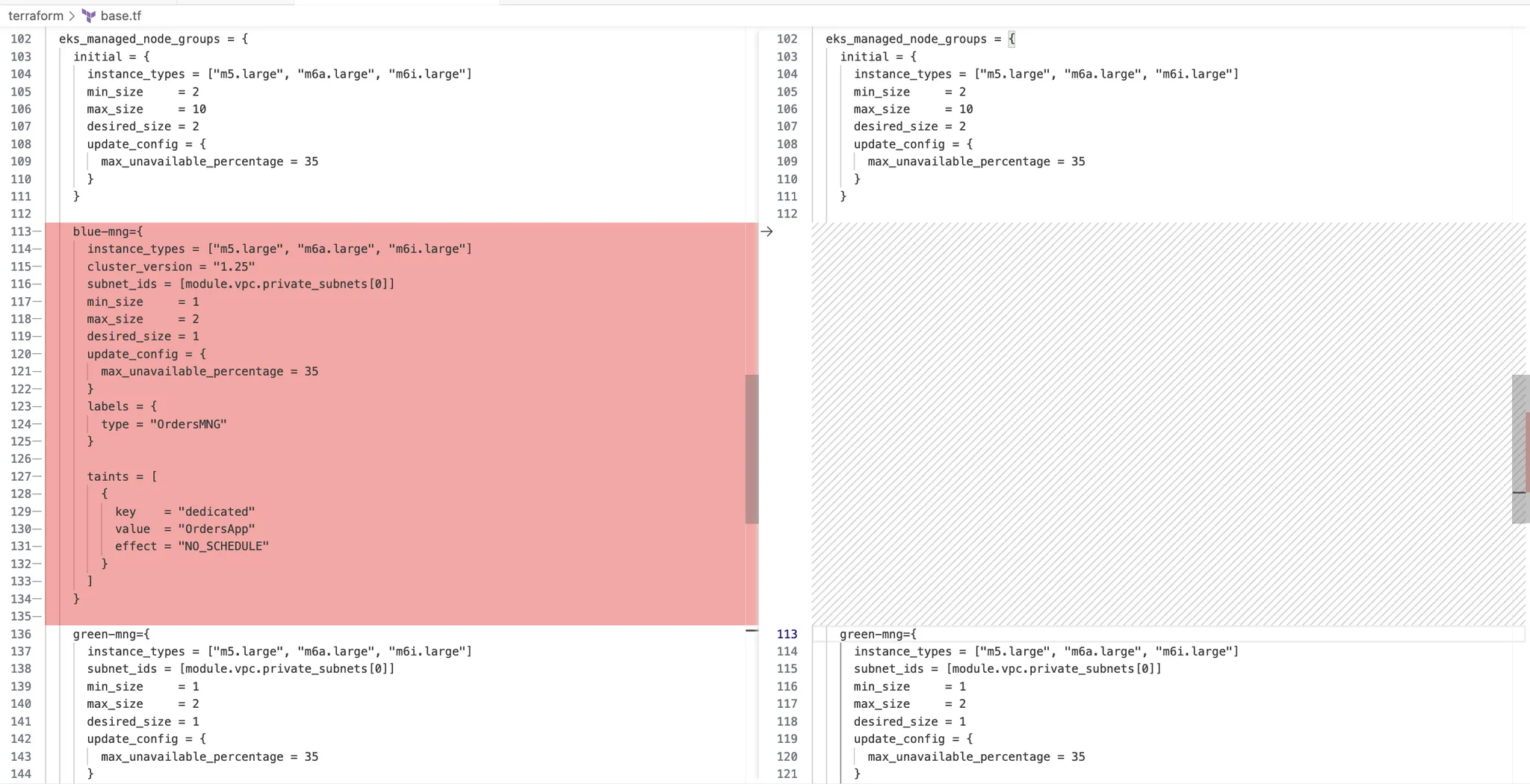
base.tf 파일에 아래 코드를 추가하여 새로운 관리형 노드 그룹 green-mng를 생성
blue-mng={
instance_types = ["m5.large", "m6a.large", "m6i.large"]
cluster_version = "1.25"
min_size = 1
max_size = 2
desired_size = 1
update_config = {
max_unavailable_percentage = 35
}
labels = {
type = "OrdersMNG"
}
subnet_ids = [module.vpc.private_subnets[0]]
taints = [
{
key = "dedicated"
value = "OrdersApp"
effect = "NO_SCHEDULE"
}
]
}
green-mng={
instance_types = ["m5.large", "m6a.large", "m6i.large"]
subnet_ids = [module.vpc.private_subnets[0]]
min_size = 1
max_size = 2
desired_size = 1
update_config = {
max_unavailable_percentage = 35
}
labels = {
type = "OrdersMNG"
}
taints = [
{
key = "dedicated"
value = "OrdersApp"
effect = "NO_SCHEDULE"
}
]
}
}# 모니터링
while true; do aws autoscaling describe-auto-scaling-groups --query 'AutoScalingGroups[*].AutoScalingGroupName' --output json | jq; echo ; kubectl get node -L eks.amazonaws.com/nodegroup; echo; date ; echo ; kubectl get node -L eks.amazonaws.com/nodegroup-image | grep ami; echo; sleep 1; echo; done
# 약 3분 소요
terraform plan && terraform apply -auto-approve
# Lets get the nodes with labels type=OrdersMNG.
kubectl get node -l type=OrdersMNG -o wide
kubectl get node -l type=OrdersMNG -L topology.kubernetes.io/zone
# Check if this node have same taints applied to it.
kubectl get nodes -l type=OrdersMNG -o jsonpath="{range .items[*]}{.metadata.name} {.spec.taints[?(@.effect=='NoSchedule')]}{\"\n\"}{end}"
# Blue-mng과 Green-mng 관리 그룹 이름 확인
export BLUE_MNG=$(aws eks list-nodegroups --cluster-name eksworkshop-eksctl | jq -c .[] | jq -r 'to_entries[] | select( .value| test("blue-mng*")) | .value')
echo $BLUE_MNG
export GREEN_MNG=$(aws eks list-nodegroups --cluster-name eksworkshop-eksctl | jq -c .[] | jq -r 'to_entries[] | select( .value| test("green-mng*")) | .value')
echo $GREEN_MNG
클러스터 업그레이드 준비 실험실에서 주문 시 PodDisruptionBudget(PDB)을 생성했다면, 배포가 1개의 복제본으로 설정되고 PDB가 minAvailable=1로 설정될 때 노드 그룹 삭제 프로세스가 차단됨. 따라서 이 문제를 해결하기 위해 복제본을 2개로 늘리기
#
kubectl get pdb -n orders
NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
orders-pdb 1 N/A 0 15h
#
cd ~/environment/eks-gitops-repo/
sed -i 's/replicas: 1/replicas: 2/' apps/orders/deployment.yaml
git add apps/orders/deployment.yaml
git commit -m "Increase orders replicas 2"
git push
# sync 를 해도 HPA로 무시로 인해 파드는 1개 유지 상태
argocd app sync orders
# apps 설정에 deploy replicas 무시 설정되어 있으니, 아래처럼 직접 증가해둘것 (이미 위에서 코드상에는 2로 변경)
# (실행 과정 중) orders 파드가 다른 노드로 옮겨감.. 실행 전에 replicas=2로 실행해두어서 좀 더 안정성 확보
kubectl scale deploy -n orders orders --replicas 2
#
kubectl get deploy -n orders
kubectl get pod -n orders

Blue-mng 관리 노드 그룹 삭제 진행
#
kubectl get node -l type=OrdersMNG
kubectl get pod -n orders -l app.kubernetes.io/component=service -owide
kubectl get deploy -n orders orders
kubectl get pdb -n orders
aws autoscaling describe-auto-scaling-groups --query 'AutoScalingGroups[*].AutoScalingGroupName' --output json | jq
while true; do kubectl get node -l type=OrdersMNG; echo ; kubectl get pod -n orders -l app.kubernetes.io/component=service -owide ; echo ; kubectl get deploy -n orders orders; echo ; kubectl get pdb -n orders; echo ; aws autoscaling describe-auto-scaling-groups --query 'AutoScalingGroups[*].AutoScalingGroupName' --output json | jq; echo ; date ; done
# 10분 정도 소요
cd ~/environment/terraform/
terraform plan && terraform apply -auto-approve
# 신규(버전) 노드 확인
kubectl get node -l eks.amazonaws.com/nodegroup=$GREEN_MNG
# 이벤트 로그 확인
kubectl get events --sort-by='.lastTimestamp' --watch

[카펜터노드] Upgrading Karpenter managed nodes
- Karpenter는 집계된 CPU, 메모리, 볼륨 요청 및 기타 Kubernetes 스케줄링 제약(예: 친화도 및 포드 토폴로지 확산 제약)을 기반으로 스케줄링 불가능한 포드에 대응하여 적절한 크기의 노드를 제공하는 오픈 소스 클러스터 오토스케일러로, 인프라 관리를 간소화합니다.
- 또한 Karpenter는 노드 그룹 및 Amazon EC2 자동 확장 그룹과 같은 외부 인프라와 용량 관리를 조정하지 않기 때문에 운영 프로세스에 대한 다른 관점을 도입하여 작업자 노드 구성 요소와 운영 체제를 최신 보안 패치 및 기능으로 최신 상태로 유지합니다.
- AWS는 새로운 Kubernetes 버전뿐만 아니라 패치 및 CVE(일반 취약점 및 노출)를 위한 AMI를 출시합니다. 다양한 Amazon EKS에 최적화된 AMI 중에서 선택할 수 있습니다. 또는 자신만의 맞춤형 AMI를 사용할 수도 있습니다.
- 현재 Karpenter에서는 EC2NodeClass 리소스가 amiFamily 값 AL2, AL2023, Bottlerocket, Ubuntu, Windows2019, Windows2022 및 Custom을 지원합니다. amiFamily of Custom을 선택하면 어떤 사용자 지정 AMI를 사용할지 Karpenter에 알려주는 amiSelectorTerms를 지정해야 합니다.
- Karpenter는 Karpenter를 통해 프로비저닝된 Kubernetes 작업자 노드를 패치하는 데 Drift 또는 **타이머(expireAfter)**와 같은 기능을 사용합니다.
Drift
Karpenter는 롤링 배포 후 Drift를 사용하여 Kubernetes 노드를 업그레이드합니다.
Karpenter를 통해 프로비저닝된 Kubernetes 노드가 원하는 사양에서 벗어난 경우, Karpenter는 먼저 새로운 노드를 프로비저닝하고 이전 노드에서 포드를 제거한 다음 종료합니다.
노드가 디프로비전됨에 따라 노드는 새로운 포드 스케줄링을 방지하기 위해 코드화되고 Kubernetes Eviction API를 사용하여 포드가 퇴거됩니다.
EC2NodeClass에서는 amiFamily가 필수 필드이며, 자신의 AMI 값인 EKS 최적화 AMI를 사용할 수 있습니다.
AMI의 드리프트는 두 가지 동작이 있으며, 아래에 자세히 설명되어 있습니다.
- Drift with specified AMI values 지정된 AMI 값을 사용한 드리프트:EC2NodeClass에서 NodePool의 AMI를 변경하거나 다른 EC2NodeClass를 NodePool과 연결하면, Karpenter는 기존 작업자 노드가 원하는 설정에서 벗어났음을 감지합니다.여러 AMI가 기준을 충족하면 최신 AMI가 선택됩니다.상태를 얻는 한 가지 방법은 EC2NodeClass에서 kubectl 설명을 실행하는 것입니다. 특정 시나리오에서는 EC2NodeClass에 의해 이전 AMI와 새로운 AMI가 모두 발견되면, 이전 AMI를 가진 실행 중인 노드들이 드리프트되고, 디프로비전되며, 새로운 AMI를 가진 작업자 노드로 대체됩니다. 새로운 노드들은 새로운 AMI를 사용하여 프로비저닝됩니다.
- 고객은 EC2NodeClass의 상태 필드에 있는 AMI 값에서 EC2NodeClass가 발견한 AMI를 추적할 수 있습니다.
- AMI는 AMI ID, AMI 이름 또는 amiSelectorTerms를 사용하여 특정 태그로 명시적으로 지정할 수 있습니다.
- 일관성을 위해 애플리케이션 환경을 통해 AMI의 promotion를 제어하는 이 접근 방식을 고려할 수 있습니다.
- Drift with Amazon EKS optimized AMIs Amazon EKS 최적화 AMI를 사용한 드리프트:AMiFamily 필드에 AL2, AL2023, Bottlerocket, Ubuntu, Windows2019 또는 Windows2022의 값을 지정하여 Karpenter에 어떤 Amazon EKS에 최적화된 AMI를 사용해야 하는지 알려줄 수 있습니다.이러한 노드는 프로비저닝이 해제되고 최신 AMI를 가진 작업자 노드로 대체됩니다. 이 접근 방식을 사용하면 이전 AMI를 가진 노드는 자동으로 재활용됩니다(예: 새로운 AMI가 있을 때 또는 Kubernetes 제어 평면 업그레이드 후).
- 이전 접근 방식인 amiSelectorTerms를 사용하면 노드가 업그레이드될 때 더 많은 제어 권한을 가질 수 있습니다.
- Karpenter는 실행 중인 EKS 버전 클러스터를 위해 지정된 최신 Amazon EKS 최적화 AMI로 노드를 프로비저닝합니다. Karpenter는 Kubernetes 클러스터 버전의 새로운 AMI가 언제 출시되는지 감지하고 기존 노드를 드리프트합니다. 상태 필드에서 EC2NodeClass AMI 값은 새로 발견된 AMI를 반영합니다.
- EC2NodeClass에 amiSelectorTerms가 지정되지 않은 경우, Karpenter는 Amazon EKS에 최적화된 AMI에 대해 게시된 SSM 매개변수를 모니터링합니다.
TTL (expireAfter) to automatically delete nodes from the cluster 클러스터에서 노드를 자동으로 삭제
- 프로비저닝된 노드에서 ttl을 사용하여 워크로드 포드가 없거나 만료 시간에 도달한 노드를 삭제할 시기를 설정할 수 있습니다. 노드 만료는 업그레이드 수단으로 사용할 수 있으므로 노드가 폐기되고 업데이트된 버전으로 대체될 수 있습니다.
- Karpenter는 NodePool의 spec.druption.expireAfter 값에 따라 노드가 만료된 것으로 표시하고 설정된 시간(초)이 지나면 노드를 중단합니다.
- 보안 문제로 인해 노드 만료를 사용하여 주기적으로 노드를 재활용할 수 있습니다.
#
aws ec2 describe-instances --query "Reservations[*].Instances[*].[Tags[?Key=='Name'].Value | [0], ImageId]" --filters "Name=tag:Blueprint,Values=eksworkshop-eksctl" --output table
# 기본 노드풀을 통해 프로비저닝된 노드가 버전 v1.25.16-eks-59bf375에 있는 것을 확인할 수 있습니다.
kubectl get nodes -l team=checkout
# Check taints applied on the nodes.
#
kubectl get pods -n checkout -o wide
# 모니터링
kubectl get nodeclaim
kubectl get nodes -l team=checkout -o jsonpath="{range .items[*]}{.metadata.name} {.spec.taints}{\"\n\"}{end}"
kubectl get pods -n checkout -o wide
while true; do kubectl get nodeclaim; echo ; kubectl get nodes -l team=checkout; echo ; kubectl get nodes -l team=checkout -o jsonpath="{range .items[*]}{.metadata.name} {.spec.taints}{\"\n\"}{end}"; echo ; kubectl get pods -n checkout -o wide; echo ; date; sleep 1; echo; done
체크아웃 애플리케이션을 확장 실습
#
while true; do kubectl get nodeclaim; echo ; kubectl get nodes -l team=checkout; echo ; kubectl get nodes -l team=checkout -o jsonpath="{range .items[*]}{.metadata.name} {.spec.taints}{\"\n\"}{end}"; echo ; kubectl get pods -n checkout -o wide; echo ; date; sleep 1; echo; done
#
cd ~/environment/eks-gitops-repo
git add apps/checkout/deployment.yaml
git commit -m "scale checkout app"
git push --set-upstream origin main
# You can force the sync using ArgoCD console or following command:
argocd app sync checkout
# LIVE(k8s)에 직접 scale 실행
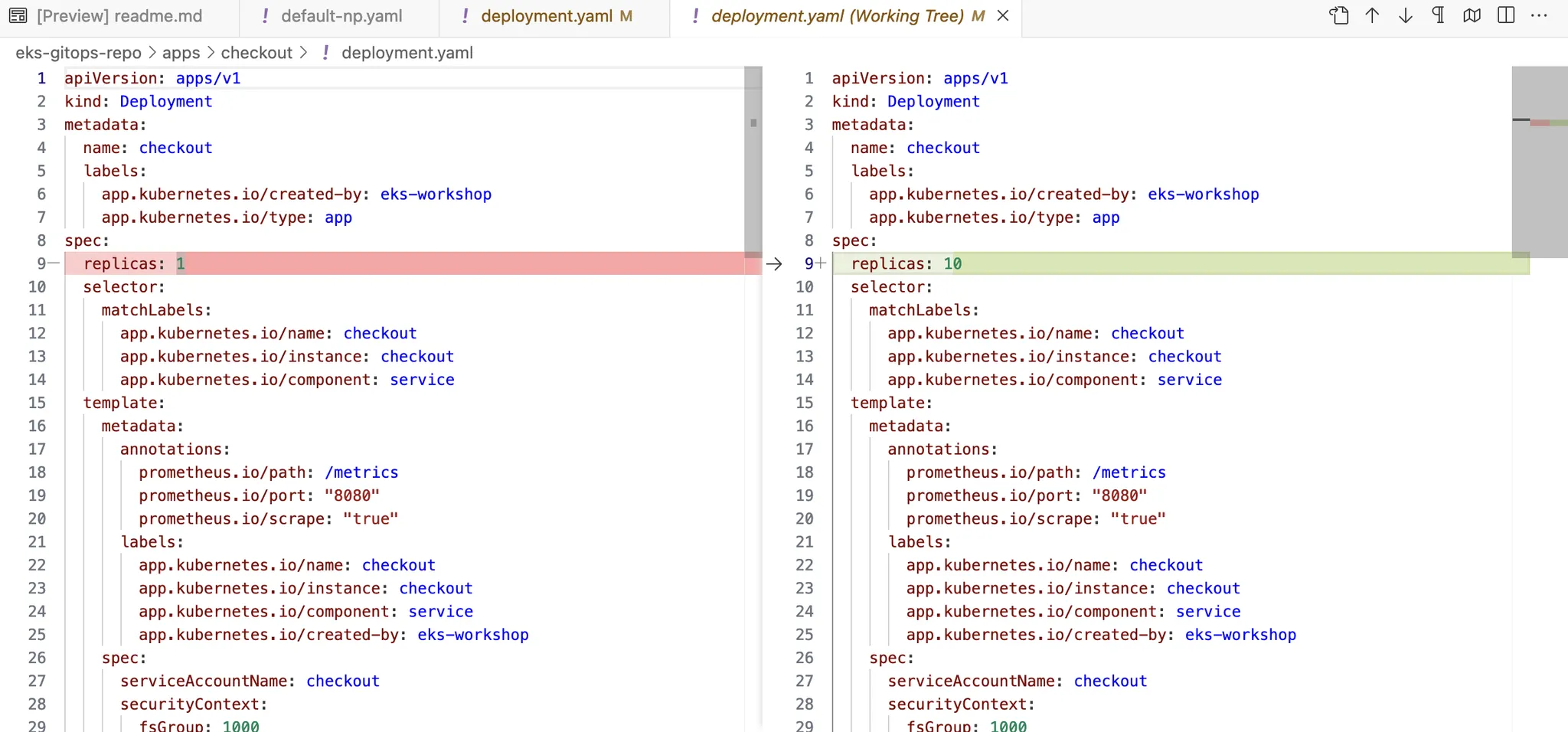
kubectl scale deploy checkout -n checkout --replicas 10
# 현재는 1.25.16 2대 사용 중 확인
# Karpenter will scale looking at the aggregate resource requirements of unscheduled pods. We will see we have now two nodes provisioned via karpenter.
kubectl get nodes -l team=checkout
# Lets get the ami id for the AMI build for kubernetes version 1.26.
aws ssm get-parameter --name /aws/service/eks/optimized-ami/1.26/amazon-linux-2/recommended/image_id \
--region ${AWS_REGION} --query "Parameter.Value" --output text

default-ec2nc.yaml에 spec.amiSelectorTerms의 AMI ID로 대체

default-np.yaml에 budgets 내용 추가

#
while true; do kubectl get nodeclaim; echo ; kubectl get nodes -l team=checkout; echo ; kubectl get nodes -l team=checkout -o jsonpath="{range .items[*]}{.metadata.name} {.spec.taints}{\"\n\"}{end}"; echo ; kubectl get pods -n checkout -o wide; echo ; date; sleep 1; echo; done
# 10분 소요 (예상) 실습 포함
cd ~/environment/eks-gitops-repo
git add apps/karpenter/default-ec2nc.yaml apps/karpenter/default-np.yaml
git commit -m "disruption changes"
git push --set-upstream origin main
argocd app sync karpenter
# Once Argo CD sync the karpenter app, we can see the disruption event in karpenter controller logs. It will then provision new nodes with kubernetes version 1.26 and delete the old nodes.
kubectl -n karpenter logs deployment/karpenter -c controller --tail=33 -f
혹은
kubectl stern -n karpenter deployment/karpenter -c controller
# Lets get the ami id for the AMI build for kubernetes version 1.26.
aws ssm get-parameter --name /aws/service/eks/optimized-ami/1.26/amazon-linux-2/recommended/image_id \
--region ${AWS_REGION} --query "Parameter.Value" --output text
ami-086414611b43bb691

Blue-Green Cluster Upgrades
신규 Green EKS 클러스터 생성
이 실험실 섹션에서는 v1.30과 원하는 구성의 새로운 EKS 클러스터를 생성합니다. 이는 블루그린 클러스터 업그레이드 전략을 사용하면 한 번에 여러 K8 버전을 뛰어넘거나 하나씩 여러 업그레이드를 수행할 수 있기 때문입니다. EKS 클러스터는 이전 클러스터와 동일한 VPC 내에서 생성됩니다. 이를 통해 여러 가지 이점을 얻을 수 있습니다:
- 네트워크 연결성: 두 클러스터를 동일한 VPC에 유지하면 리소스 간의 원활한 통신이 보장되어 워크로드와 데이터를 더 쉽게 마이그레이션할 수 있습니다.
- 공유 자원: NAT 게이트웨이, VPN 연결, Direct Connect와 같은 기존 VPC 자원을 재사용할 수 있어 복잡성과 비용을 줄일 수 있습니다.
- 보안 그룹: 두 클러스터 모두에서 일관된 보안 그룹 규칙을 유지하여 보안 관리를 간소화할 수 있습니다.
- 서비스 검색: AWS 클라우드 맵 또는 유사한 서비스 검색 메커니즘을 사용하면 서비스가 클러스터 간에 서로를 더 쉽게 찾을 수 있습니다.
- 서브넷 활용: 기존 서브넷을 효율적으로 활용할 수 있어 새로운 네트워크 범위를 프로비저닝할 필요가 없습니다.
- VPC 피어링: VPC가 다른 VPC와 피어링되는 경우, 이러한 연결은 두 클러스터 모두에서 유효하게 유지됩니다.
- 일관된 DNS: 동일한 VPC를 사용하면 프라이빗 DNS 존과 Route 53 구성을 일관되게 사용할 수 있습니다.
- IAM 및 리소스 정책: 많은 IAM 역할과 리소스 정책이 VPC에 적용되므로 동일한 VPC를 사용하면 권한 관리가 간소화됩니다.
이전에 생성된 EFS 파일 시스템의 ID를 검색 (StatefulSet Resources를 생성할 때 사용)
#
export EFS_ID=$(aws efs describe-file-systems --query "FileSystems[*].FileSystemId" --output text)
echo $EFS_ID
실습
#
watch -d 'aws ec2 describe-instances --filters "Name=instance-state-name,Values=running" --query "Reservations[*].Instances[*].[InstanceId, InstanceType, PublicIpAddress]" --output table'
#
cd ~/environment
unzip eksgreen.zip
tree eksgreen-terraform/
#
cd eksgreen-terraform
terraform init
terraform plan -var efs_id=$EFS_ID
terraform apply -var efs_id=$EFS_ID -auto-approve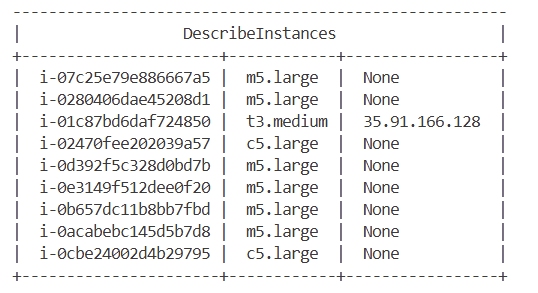

Update Kubectl Context : 별칭 사용
#
aws eks --region ${AWS_REGION} update-kubeconfig --name ${EKS_CLUSTER_NAME} --alias blue && \
kubectl config use-context blue
aws eks --region ${AWS_REGION} update-kubeconfig --name ${EKS_CLUSTER_NAME}-gr --alias green && \
kubectl config use-context green
#
cat ~/.kube/config
kubectl ctx
kubectl ctx green
# Verify the EC2 worker nodes are attached to the cluster
kubectl get nodes --context green
NAME STATUS ROLES AGE VERSION
ip-10-0-20-212.us-west-2.compute.internal Ready <none> 21m v1.30.9-eks-5d632ec
ip-10-0-21-169.us-west-2.compute.internal Ready <none> 21m v1.30.9-eks-5d632ec
ip-10-0-35-26.us-west-2.compute.internal Ready <none> 21m v1.30.9-eks-5d632ec
ip-10-0-9-126.us-west-2.compute.internal Ready <none> 21m v1.30.9-eks-5d632ec
# Verify the operational Addons on the cluster:
helm list -A --kube-context green
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
argo-cd argocd 1 2025-03-26 11:58:02.453602353 +0000 UTC deployed argo-cd-5.55.0 v2.10.0
aws-efs-csi-driver kube-system 1 2025-03-26 11:58:30.395245866 +0000 UTC deployed aws-efs-csi-driver-2.5.6 1.7.6
aws-load-balancer-controller kube-system 1 2025-03-26 11:58:31.887699595 +0000 UTC deployed aws-load-balancer-controller-1.7.1 v2.7.1
karpenter karpenter 1 2025-03-26 11:58:31.926407743 +0000 UTC deployed karpenter-0.37.0 0.37.0
metrics-server kube-system 1 2025-03-26 11:58:02.447165223 +0000 UTC deployed metrics-server-3.12.0 0.7.0

Stateless Workload Migration
- Stateless application upgrade process이 워크숍에서는 이미 AWS CodeCommit eks-gitops-repo에 리테일 스토어 앱의 진실 소스를 생성하고 ArgoCD를 사용하여 Blue 클러스터에 배포했습니다. 이러한 진실 소스를 확보하는 것은 Blue-Green 클러스터 업그레이드를 수행하는 데 있어 매우 중요합니다. 따라서 eks-gitops-repo로 새 클러스터를 부트스트랩하여 애플리케이션을 배포하기만 하면 됩니다.
- 부트스트래핑 전에 최신 1.30 K8S 버전을 준수하도록 애플리케이션을 변경해야 합니다. 클러스터 업그레이드 준비 모듈에서 설명한 것처럼, EKS 업그레이드 인사이트, kubent와 같은 도구를 사용하여 사용되지 않는 API 사용량을 찾아 이를 완화할 수 있습니다.
- 상태 비저장 애플리케이션은 클러스터에 영구 데이터를 보관할 필요가 없으므로 업그레이드 중에 새 녹색 클러스터에 배포하고 트래픽을 라우팅하기만 하면 됩니다.
GitOps Repo Setup : UI HPA 수정
부트스트래핑 프로세스 시작
그린 클러스터에 필요한 변경 사항을 분리하기 위해 새로운 git 브랜치를 사용하여 수정 사항을 유지하고 이 브랜치를 사용하여 그린 클러스터를 부트스트랩할 예정입니다.
#
cd ~/environment/eks-gitops-repo
git status
git branch
* main
# Create the new local branch green
git switch -c green
git branch -a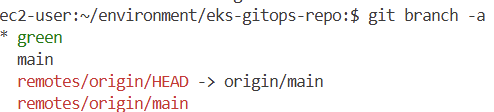
관련 K8s 매니페스트를 1.30개의 세부 정보로 업데이트하세요. 예를 들어, 1.26 Amazon Linux 2 AMI와 IAM 역할 및 보안 그룹의 블루 클러스터를 참조하는 Karpenter EC2NodeClass가 있습니다. 따라서 1.30 Amazon Linux 2023 AMI와 그린 클러스터의 보안 그룹 및 IAM 역할을 사용하도록 업데이트해 보겠습니다. 다음 명령으로 AL2023 AMI를 가져옵니다.
export AL2023_130_AMI=$(aws ssm get-parameter --name /aws/service/eks/optimized-ami/1.30/amazon-linux-2023/x86_64/standard/recommended/image_id --region ${AWS_REGION} --query "Parameter.Value" --output text)
echo $AL2023_130_AMI
default-ec2nc.yaml에서 AMI ID, 보안 그룹, IAM 역할 및 기타 세부 정보를 업데이트합니다.
cat << EOF > ~/environment/eks-gitops-repo/apps/karpenter/default-ec2nc.yaml
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
metadata:
name: default
spec:
amiFamily: AL2023
amiSelectorTerms:
- id: "${AL2023_130_AMI}" # Latest EKS 1.30 AMI
role: karpenter-eksworkshop-eksctl-gr
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: eksworkshop-eksctl-gr
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: eksworkshop-eksctl
tags:
intent: apps
managed-by: karpenter
team: checkout
EOF
이제 1.30에 비해 사용되지 않는 API 사용량을 확인해 보세요. GitOps 저장소에서 사용되지 않는 API 사용량을 찾을 수 있도록 Pluto 유틸리티를 미리 설치했습니다.
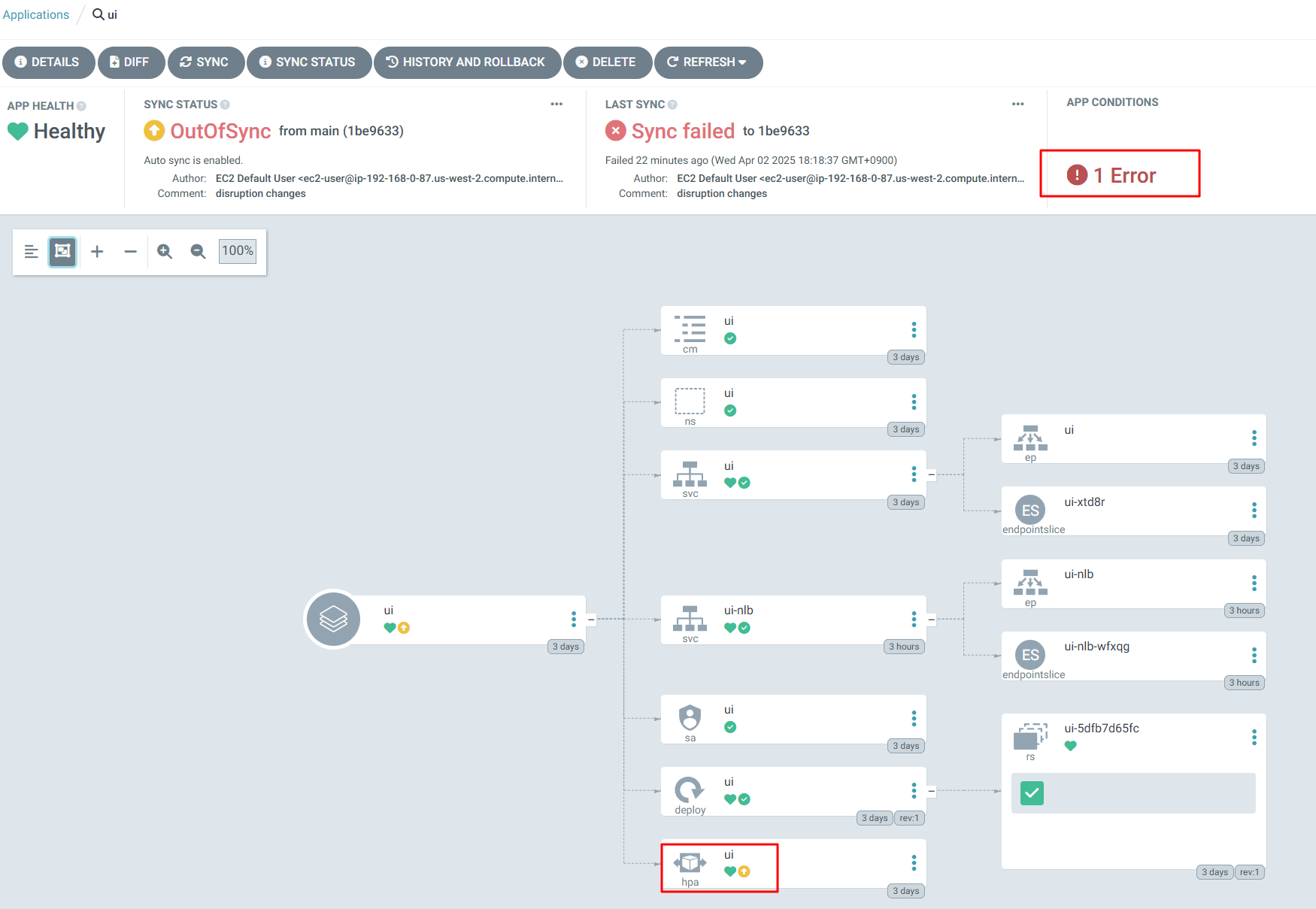
# 위에서 미리 조치를 해서 안나오지만, 미조치했을 경우 아래 처럼 코드 파일 내용으로 검출 가능!
pluto detect-files -d ~/environment/eks-gitops-repo/
NAME KIND VERSION REPLACEMENT REMOVED DEPRECATED REPL AVAIL
ui HorizontalPodAutoscaler autoscaling/v2beta2 autoscaling/v2 false true false
#
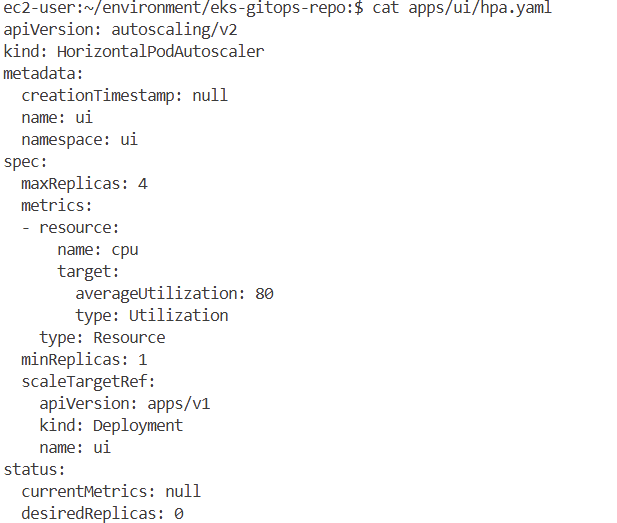
kubectl convert -f apps/ui/hpa.yaml --output-version autoscaling/v2 -o yaml > apps/ui/tmp.yaml && mv apps/ui/tmp.yaml apps/ui/hpa.yaml
#
cat apps/ui/hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: ui
namespace: ui
spec:
minReplicas: 1
maxReplicas: 4
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: ui
metrics:
- resource:
name: cpu
target:
averageUtilization: 80
type: Utilization
type: Resource

마지막으로 녹색 브랜치를 사용하도록 ArgoCD 앱 애플리케이션을 가리킵니다.
#
cat app-of-apps/values.yaml
#
sed -i 's/targetRevision: main/targetRevision: green/' app-of-apps/values.yaml
# Commit the change to green branch and push it to the CodeCommit repo.
git add . && git commit -m "1.30 changes"
git push -u origin green
ArgoCD Setup on Green EKS Cluster
# Login to ArgoCD using credentials from the following commands:
export ARGOCD_SERVER_GR=$(kubectl get svc argo-cd-argocd-server -n argocd -o json --context green | jq --raw-output '.status.loadBalancer.ingress[0].hostname')
echo "ArgoCD URL: http://${ARGOCD_SERVER_GR}"
export ARGOCD_USER_GR="admin"
export ARGOCD_PWD_GR=$(kubectl -n argocd get secret argocd-initial-admin-secret -o jsonpath="{.data.password}" --context green | base64 -d)
echo "Username: ${ARGOCD_USER_GR}"
echo "Password: ${ARGOCD_PWD_GR}"
# Alternatively you can login using ArgoCD CLI:
argocd login --name green ${ARGOCD_SERVER_GR} --username ${ARGOCD_USER_GR} --password ${ARGOCD_PWD_GR} --insecure --skip-test-tls --grpc-web
Register the AWS CodeCommit Git Repo in the ArgoCD:
#
argo_creds=$(aws secretsmanager get-secret-value --secret-id argocd-user-creds --query SecretString --output text)
argocd repo add $(echo $argo_creds | jq -r .url) --username $(echo $argo_creds | jq -r .username) --password $(echo $argo_creds | jq -r .password) --server ${ARGOCD_SERVER_GR}
Repository 'https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo' added
Deploy the retail-store-sample application components on the green cluster, we are using ArgoCD App of Apps patterns to deploy all components of the retail-store-sample
#
argocd app create apps --repo $(echo $argo_creds | jq -r .url) --path app-of-apps \
--dest-server https://kubernetes.default.svc --sync-policy automated --revision green --server ${ARGOCD_SERVER_GR}
'k8s > AWS EKS' 카테고리의 다른 글
| [AWS] EKS Mode/Nodes (1) | 2025.03.22 |
|---|---|
| [AWS] EKS Security (0) | 2025.03.16 |
| [AWS] EKS AutoScaling (0) | 2025.03.08 |
| [AWS] EKS Observability (0) | 2025.03.01 |
| [AWS] EKS Storage (0) | 2025.02.23 |



